The Illogical Logic of Agents: Why They Suck and What We Can Do About It
The Eightfold Path to Better Agents


If you think AGI is just around the corner, try building an agent.
And I don't mean a "talk to your PDF" or scrape this website with Playwright agent. Those are good, useful tools, but they hardly qualify as complex thinking and reasoning systems. I mean try to build a real one.
What's a real agent?
An AI system that's capable of doing complex, open ended tasks in the real world.
Even more complicated?
Build an agent that can do long-running, open ended tasks. Like a person.
The real world could be the physical world or online. What we're talking about here is when agents get out of the lab and face the never ending complexity of life.
Life is messy.
Try to build an agent that deals with the barely restrained chaos of real life and you'll realize just how dumb these systems currently are.
If you work with agents every day, like my team does, you quickly see the limitations of today's frontier models. We see the same problems again and again and we divide those problem into three broad areas that we affectionately call:
Big brain
Little brain
Tool brain
"Big brain" means anything that deals with higher level reasoning, strategic long and short term planning, abstraction, expert understanding and common sense. As we'll soon see these are the biggest problems we run into and we'll talk about some potential fixes but this is the hardest area to make stronger.
Here's a simple example that seems trivial to you but is hard for machines: solving the problem of "I'm thirsty."
You run through scenarios like I could have a Coke, or OJ, or water. Do we have enough filtered water in the house? No, I have to run to the store. Do I really want to run to the store just so I don't have to drink tap water? Yes. Okay, I have to put on my jacket, take my wallet and keys, go to the store to buy filtered water so I can satisfy my thirst.
There's a cascade of steps here from making a decision, getting dressed, taking your keys and money, closing the door, locking up, heading to the store, finding the water, buying it and drinking it.
Moravec's paradox says that reasoning for robots is relatively easy and sensorimotor perception is hard. That's wrong. Both are hard, especially when you try to generalize reasoning.
We can also think of this as strategic reasoning.
"Little brain" means the thinking and planning of precise in-the-moment actions or steps, like a UI navigating agent that needs to find the right button or a robot that has to decide whether the thing in front of it is a tree or a stop sign or a half broken wall.
Each step on our journey is a cluster of sub-actions specific to the major milestone we're on. If I'm checking out with my bottled water, there's picking the shortest line, waiting on that line, stepping forwards, answering questions like if I want a bag or not, small talk with the checkout person, and how do I want to pay?
You can think of these as an atomic sub-cluster of reasoning tasks. Another way to think of it is tactical reasoning.
If I want to drink my drink, that's another cluster of actions that "Little Brain" handles. At the unconscious level my brain says I need to reach out my arm, open my hand, close it around the bottle firmly, pick it up, twist off the cap with my other hand, tilt the bottle back to my lips.
"Tool brain" is the quality and precision of the tooling/appendages/sensors/APIs/real world interfaces given to the model/robot to execute an action. It doesn't matter if the little brain figures out it needs to click the "search" button if the tool itself to return those coordinates is problematic. It's like having a broken hand.
You may know you want to pick up the bottle in front of you, as well as the right steps to do it but if your hand isn't working right you can't pick it up.
None of these problems are easy to solve. None of them work "right out of the box" with today's foundation models. Some of them are made easier by the emergent capabilities of these models but there's a tendency to believe these models are magic that can do anything easily with no work involved.
It doesn't take very long working with agents in the real world to be disabused of that notion fast.
We're going to talk about each of these and we're going to talk about how we can fix them in the future and what it will take to do it.
In essence, every agent today is a beautiful snowflake, a complex mash-up of multiple models, human integrated logic, heuristics, fine tuning, error correction and scoping, not to mention chewing gum, glue code and fantastical, multi-layered prompt engineering.
Let's take a look at big brain reasoning first and why it's the hardest part to solve.
Big Sky Mind

(Image: Midjourney 6.1)
When we're talking about reasoning we're talking about the "thinking" capabilities of today's foundation/frontier models like o1-preview/mini/o1, GPT-4o, Claude 3.5, Llama 3.1 405B and Gemini. Usually we're calling these models through an API to a proprietary cloud service, though we might be running LLama 3.2 in our own private cloud or datacenter.
There's a cost with the round trip time to the cloud and a cost imposed by how brilliantly or how crappy these cutting edge models make decisions.
So how do they make decisions?
Amazingly and then horribly. In an endless loop.
Even worse, as the task gets longer and more involved their errors cascade. It's a compounding problem. A mistake in one part of the task can carry down into other parts of the task and corrupt all the steps after.
A classic example is that the top models today tend to hallucinate the old version 1 style of OpenAI's API to talk to the model. The old style was written like this:
response = openai.ChatCompletion.create(
The new way is written like this:
response = client.chat.completions.create(
These models will routinely swap out the old method for the new and now every step they took that is related to that mistake is wrong.
This is just a simple example but one that happens all the time, even when you give the model the latest documentation. It will often switch to the new style after you correct it, but after 10 or 20 steps its contextual memory buffer will overflow and it will revert back to the old way of doing things.
This happens even with reasoning models like o1-preview and o1-mini.
It often feels like working with a brilliant idiot. These models are capable of incredible decision making at times and then they just do something that makes absolutely no sense.
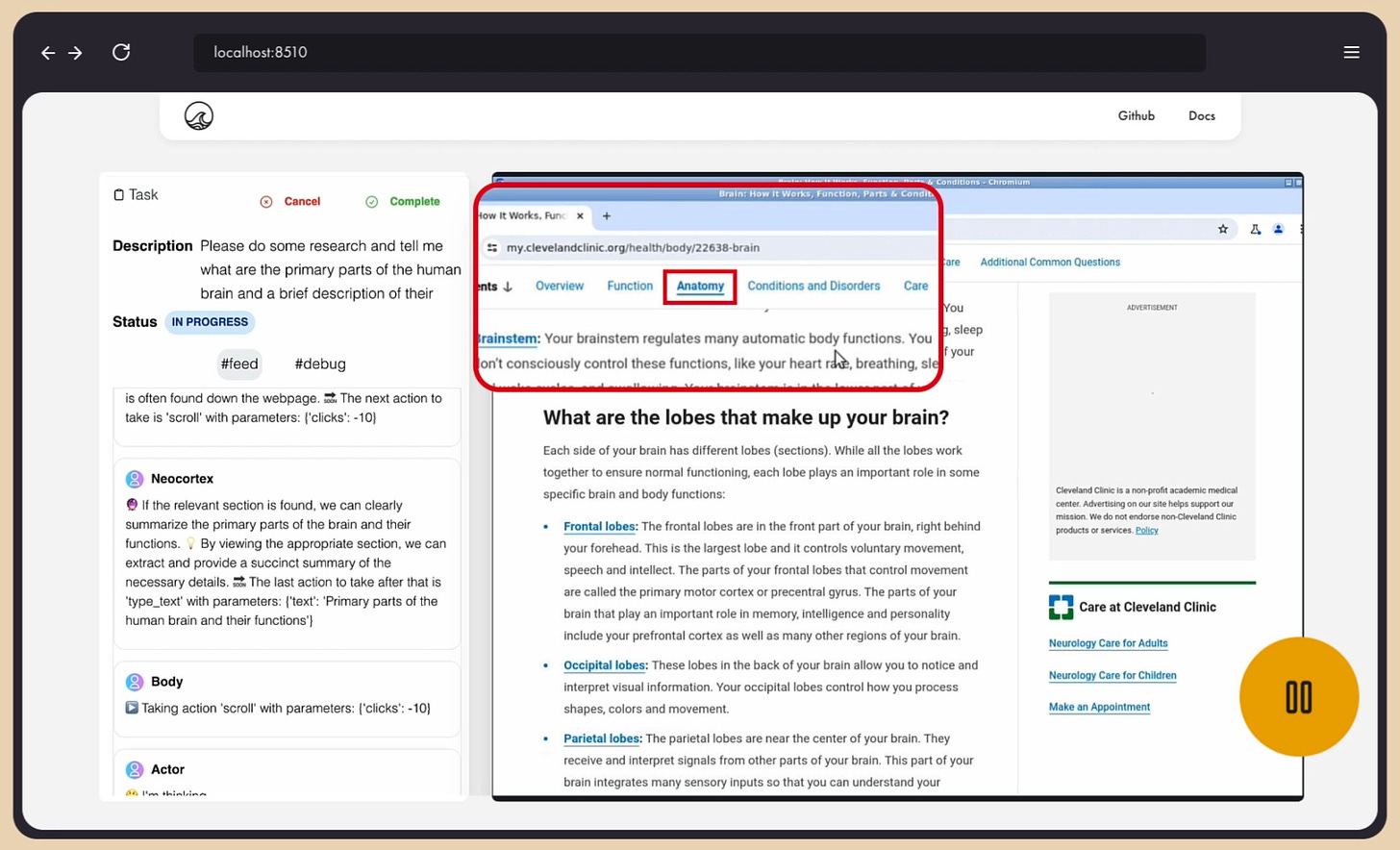
In this experimental version of our next-gen GUI navigating agent, you can see it make generally good decisions and some dumb ones too. The prompt was "Go to Wikipedia and tell me the countries that Edward the Confessor was king of during his lifetime."
In the video the browser was already open because I was running multiple variations of the test. The agent correctly reasoned to use Ctrl+L to automatically highlight the URL bar. It then correctly guessed the page, either pulling from its memory system (which I'm testing here) or just by deducing the general structure of the page names. All good.
Then it decides it needs to click the "language" setting for some reason and to scroll up and down for reasons unknown, instead of just reading the page.
Even worse, it hallucinates several "tools" that it does not have access to, despite having a list of tools to choose from that help it find GUI elements, decide coordinates to click on, take screenshots and more. It decides it needs to use the "read_text" tool which does not exist. It straight made it up. The main model running here is GPT-4o and it forgets that it has built in OCR and reading capabilities and that it doesn't need an external tool to read anything.
At one point I just hacked the hallucination by creating a dummy tool called, read_text that returned text that said "You DO NOT need this tool. Don't use it. You have a built-in ability to read text as a powerful frontier model. Just read it. Don't call this again."
That made it worse.
The model would often just get stuck in a loop calling read_text or analyze_page or any other set of fake tools it could imagine in an endless loop, failing to complete the task, even though it already had the answer (from reading it!) and all it had to do was trigger the "I think the task is done" loop to give the answer to the user and end the run.
In other runs, I watched the bot fail to open the web browser, something it successfully did 99.5% of the time. It decided that the "web browser" was the "agentsea home folder" for reasons that only its digital neurons know the mystery of and it failed to get past stage one of a task it had completed a 1000 times before with ease.
Welcome to the absurd reasoning of the big brain.
Every team I've talked to that's building agents has pivoted from "we'll build a general purpose agent" to building a "narrow agent" where they've drastically pruned the scope of their ambitions and surrounded a Multimodal Large Language Model (MLLM) with expert heuristics and guardrails and smaller models to compensate for the absurd reasoning of MLLMs.
What do I mean by absurd reasoning?
I mean these machines completely lack basic common sense, not to mention consistent and clear deductive and inductive reasoning and they struggle with strategic thinking and building a complete world model.
Common sense and lack of a world model are perhaps the biggest problems.
"Common sense" is a series of built-in abstract patterns that we recognize in almost any variation or configuration without even realizing it.
A "world model" is an abstracted understanding of the world around us. If you get cut by a knife one time, you abstract the concept of "pain" and "sharp." Now you can see any jagged object like a rock, a spike on a fence, a pike, a sword and you know it’s dangerous.
A multimodal model has to see pictures of a knife from the side, low angles, high angles, overhead, front and back during its training or it has no idea this is the same concept and should be grouped together and it can't generalize what it learned to other sharp objects easily.
Meanwhile, a fish knows this automatically (and so do you). You can show a fish a picture of a frog and train it to get food if it touches that picture. Now give the fish a new picture of the frog at a different angle and it will instantly know that it's still a frog and swim right up to it to get that food.
An experiment in 2022 by comparative psychologist Caroline DeLong at Rochester Institute of Technology did the above experiment with goldfish.
As Max Bennett writes in his amazing book A Brief History of Intelligence: "Amazingly, the fish swam right up to the new frog picture, clearly able to immediately recognize the frog despite the new angle."
In other words, the fish (and you) have a built in understanding of 3D that it can generalize to any object it sees from only a single angle.
So how does this lack of common sense show up in agents?
Let's say the agent misclicks a form. It meant to click the name field and misclicked.
What does it do then?
Sometimes it figures out it didn't click the form but other times it just starts typing anyway! Even worse, sometimes it doesn't seem to recognize that it failed to fill out the form, even from an updated verification screenshot showing that the form field is empty.
Here's an agent about to click the submit button on Wikipedia even though it never managed to type anything in the search field.

A human just would almost never do that.
You would know the field was empty and something went wrong. (Well most would. You should see some of my old IT consulting clients but that's a story for another day...)
Besides my ex-clients I say almost because sometimes someone has no software experience whatsoever or they never learned about interfaces. But most people who've used a search engine or Wikipedia before would never make this mistake except under extreme circumstances like they're badly drunk or trying to do too many things at once and not really paying attention.
We take common sense for granted but it's a powerful map of the world and a quick and easy way for our brains to understand what's happening without having to burn too much energy. Common sense delivers lightning fast micro-understandings that happen just under the surface of our consciousness, helping us every single second of every day.
Your brain is constantly monitoring for tiny micro-signals that something is "right" or "wrong" and it happens seamlessly, easily and automatically.
If you were naked and I told you to run down to the store you'd have the common sense to know you should probably put some clothes on, even though I never explicitly told you that.
Here's another example from Max Bennett. I started with the line "He threw a baseball 100 feet above my head, I reached up to catch it, jumped..." and let it finish the sentence.

Because of your common sense, you'd know the ball was too high to catch.
GPT-4o does not know that.
Usually.
Every once in a while it gets it but that's the nature of these systems. When it comes to task consistency, every once in a while doesn't cut it.
Don't get me wrong. Many of these systems are still good and useful and they do things that simply weren't possible a few years ago.
I wrote one knowledge assistant that went out and crawled 30K websites of potential partners and the bot summarized what they do, found their current pricing and scored them according to a hand crafted selection criteria in a function call. It saved our team a massive amount of time. It would have taken us months to go read all those sites manually.
But the bot also sucked too. It was like playing edge case whack-a-mole. It was not easy to get right and it took about a month of hacking away and adding checks and balances and prompt engineering to make it work.
That's still a far cry from just talking to a super smart machine and giving it the broad strokes of what you want and having it go out and figure out the whole task on its own and do it effectively with minimal supervision, checking in every few hours or days with questions, follow ups and adjustments.
This is not "Her."
Every single agent today is a bespoke work of art, a beautiful little snowflake that some team slaved over for months to get working. They're hand crafted marvels of overlapping traditional AI methods, prompt engineering, creative thinking, hand written code, hacks, heuristics, and chewing gum to hold it all together.
And no GPT-5 or Claude 4 are not just going to "solve everything."
They won't.
Neither is GPT 6 or Ilya Sutskever's SSI and its "straight shot to superintelligence."
And now we know, neither will Project Strawberry, aka o1, o1-preview and o1-mini, just as I predicted in my article Why LLMs are Much Smarter Than You and Much Dumber Than Your Cat a few months ago. They're awesome models but they're only good at learning the hard reasoning of math and science and are not good at the fuzzier reasoning of people.
But it's not just higher level reasoning where today's agents fall short.
And that's where Little Brain comes into the picture.
Little Brain, Big Problems
Reasoning about sequences of steps is partly a Big Brain problem and partly a Little Brain problem.
Little Brain reasoning problems can be simple or complex. Simple is just knowing the correct action to take. Complex is not knowing the right chain of actions to take. In one test of our GUI nav agent, I had the model open Gmail, write a poem and send it to the team. It did all that.
Then it made a Little Brain tactical understanding mistake. It decided that it needed to verify that the email was sent, because we hadn't given it a memory of previous actions yet, so it had no memory of what it just did.
It decided that in order to check that the email was actually sent it needed to click on "drafts" instead of the "sent" folder.

That's wrong reasoning about what to do, so the mistakes can easily compound from there.
In this case it was hilariously wrong. It noticed that there were 3 previous failed attempts in drafts from earlier tests and it proceeded to start sending all of them, in a perfect example of terrible Little Brain reasoning.
Common sense also comes in at this level too.
When you're clicking around a GUI, you have an intuitive sense of whether it's giving you the right "feedback" after you did something. Your brain is always running a background heuristic to tell you if what is happening is "right." You don't know where that sense comes from, but you just know. What's really happened is that your brain has generalized the patterns of "using software" and "sending email" and you are drawing from that rich knowledge in parallel as you take actions.
If you click on a button, but it didn't light up or get highlighted in some special way, you know it didn't get clicked because the outcome didn't match your expectations, even if you're not consciously aware of it.
If you tried to type in the Departure field on Google Flights and no numbers show up, you know you didn't click on the right part of the form. If you start typing and the first letter doesn't show up, you go back and correct it before continuing.
Frontier models often can't do any of this very well. They have no sense of inherent rightness of the feedback from their tasks. Some of that is a tool problem, which we'll get into in a moment, but some of it is just Little Brain reasoning.
Another example of broken tactical reasoning came to me as I was watching my GUI nav agent try to navigate a calendar on Google Flights. At one point it tried to click on the "departure" date field and misclicked and ended up on "return." Instead of going back to "departure" it decided that it would select the "return" date number since it was already there and then it would just click the "departure" date right after. But the interface was designed for humans and human reasoning. Clicking the return first and then the departure date is just something we never think to do. We go in order of departure and then return. This habit and reasoning is so engrained in humans that the designers of the interface never even considered someone would click "return" first.
So what happens?
As soon as the agent goes back and clicks the departure date, it resets the return date and all that work was wasted because the workflow just never anticipates that anyone would ever do that. Now it has to click the return date again.
Here's one I saw today: The agent misclicked on Google Flights and typed the departure destination into the departure date field. Many calendars don't let you type but the Google Flight calendar does.

That was partly a problem of Tool Brain because the click model returned the wrong field and it happily clicked that field. But the real deeper problem came with Little Brain. A mistake like this is recoverable but you have to realize it's a mistake.
A human would figure it out instantly.
But the agent?
It got a verification screenshot in order to make sure what it just did was right. Here's what it thought when it saw that screenshot:
"The 'From' field has been successfully updated to 'JFK,' indicating that the subtask to enter 'JFK' has been completed. Additionally, the calendar input suggests the next step of entering the corresponding date."
It's not always this bad. Sometimes these model know exactly what to do. Their built in reasoning is good enough and they know the general steps to take to navigate a GUI to do a basic task like look up some information on Wikipedia.
But sometimes they still can't do it because their hands are broken or they're blind.
The Right Stuff
We take for granted the magnificent tools that evolution gifted us.
Our eyes are evolutionary masterpieces, capable of fast fine grained tracking of objects and processing massive amounts of information and knowing exactly what to focus on.
"Your eye can detect over 10 million color hues" and process "36,000 pieces of information per hour" and "24 million images in your lifetime."
And what of your ears, your perfect ears?
They're masterful, in-hardware audio transmutation masters. They're Fast Fourier Transform marvels, able to convert sound in an instant and send it to our brain for instant understanding.
I could talk endlessly about the beauty of hands and fingers, the most exquisite fine grained object manipulators in the known Universe. Our hands are a single, universal tool that lets a baseball outfielder snatch a ball out of the clear blue sky, whirl on a dime and hurl the ball across 400 feet of glittering green grass and hit a catcher right in the glove at home plate with unbelievable precision.
As the ball leaves the player’s finger tips, even a tiny fraction of an inch to the left or the right will change the arc of the parabola of the ball and send it wide right or wide left and yet professional baseball players can make this throw with almost superhuman ease, hitting the catcher with tremendous precision.
That same tool let Da Vinci paint the Mona Lisa, his fingers delicately weaving the soft lines of her smile. We use the same tool to eat, take out the trash, fold clothes, swing a sword, fire a gun, do pushups, write beautiful poetry, swing a hammer, type on a keyboard and so much more.

(Image: Midjourney 6.1)
With tools like that, is it any wonder we can do wonders?
But our agent tools are not so refined just yet.
This is no surprise. We haven't been at it all that long and evolution has been at it for billions of years.
Roboticists have been discovering the pain of building precise manipulation appendages for many decades. They have a much healthier understanding of the scope of the problems that software only agent developers are just starting to figure out now.
That's where Morvec's paradox was coined. Basically all the stuff that happens at the unconscious level, that we take for granted, is incredibly hard to model in AI systems. As we saw earlier, the paradox is only half right, because it is all hard.
Actually, I'd argue we've made more progress on sensorimotor perception and locomotion than we have on reasoning over the past forty years but precision tooling is still a major problem in physical agents and online agents too.
In my article on our second gen agent, Robbie G2, I talked about some of Robbie's tools. We've refined them since then and given him more tools to use but the tools still make mistakes.
One of our tools we call "grid" because we layer a grid of numbers over an image and ask the foundation model what number is the thing you're looking for closest to? Then we can zoom in on that area and ask the question again, zeroing in on what the agent is looking for on that step.
It works because while today's foundation models aren't particularly good at giving precise coordinates they're good at giving approximate locations, like "the compose button on twitter is near the number '7'."
It generally works pretty well overall but we noticed Robbie G3 was still struggling with calendars. After looking deeper at the problem, we saw that it was multilayered but the biggest problem was a Tool Brain problem.
On the third and final zoom in, the red circles were blocking or partially obscuring many of the numbers, so the agent really had no chance of picking the right number.

We ended up crafting an entire calendar doctor sub-tool that can detect a calendar with an OCR model and reconstruct it mathematically, even when it doesn't properly OCR every number.

Better tool. Better results.
Tool Brain problems can be subtle and easy to miss too.
One of the biggest Tool Brain problems right now is that Robbie is always looking at the past. That's because our agent is not really looking at the screen in real time like we do. It's looking at a screenshot, which is a snapshot of the past, like looking at the light of a star.
When you look at a star, you're not really looking at the star as it is now, you're seeing it as it was millions of years ago, because it took that long for the light to travel to you. Screenshots are not a million years old but they are the past. Sometimes something changes before the agent can see it in the time it took to generate that screenshot, pass it to the foundation model in the cloud, reason about the next action and take that action.
A sudden pop-up may obscure a view that was visible, but the pop up showed up just after the screenshot was taken. Multiple screenshots help to give the agent a sense of transition but it's still not real time.
The agent is not watching itself type in the way that you are and until we have agents that can process video in real time we won't be able to build that kind of feedback into the agent.
Tesla had to move most of their object detection and object recognition of trees/cars/roads/signs/people into hardware to get the best real time view of the world, processing video at 30 frames per second. That's the very definition of better tooling.
Our tools will get better over time. So will Big Brain and Little Brain.
But what does it take to get there?
Dancing Strawberries and the The Bitter Lesson Strikes Back, Again

Project Strawberry, aka OpenAI's o1 models, points to a partial answer and so does the bitter lesson.
A complete answer will take new algorithms and breakthroughs in machine learning.
But that doesn't mean we can't get much better agents today.
The three keys to making progress are:
Reinforcement learning (RL)
Learnable/generalizable algorithms
Scale
RL may not give us magical AGI (to the great disappointment of many AI hype masters who thought Strawberry might be some mystical, supernatural AI from the future) but it can give us better task management, better task understanding and better agents.
Strawberry is a reinforcement learning technique where OpenAI trained the model on Chain of Thoughts, aka "let's think about this step by step." It helps the model correct errors, see its thoughts and critique them and correct them much better than earlier models.
As for the Bitter Lesson of Richard Sutton:
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin."
Most folks think that Sutton just meant scale is king, aka GPUs go burr, but it's a bad misreading of what he said. Scale is important, both on training and inference. But there's much more at work here. Later in the same post he writes a strong clarification:
"AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning."
The example of the power of pure learning and search is illustrated perfectly by the evolution of AlphaGo to AlphaGo Zero.
Most folks know the story of AlphaGo and how it beat Lee Sedol, the best player in the world 4-1 but they don't know the story of AlphaGo Zero.
AlphaGo was a supervised learning and exploration system. It learned policies from human games and it had a lot of expert logic tuned into it over time. It was an incredible system. But what came after it was more incredible.
AlphaGo Zero had only the basic rules of Go to start from and then it played itself over time, spawning new versions of itself and evolving its understanding through experience and trial and error. It had no human games to learn from or advanced expert characteristics lovingly woven in by its creators.
After only 3 days of training, AlphaGo Zero smashed AlphaGo in head to head competition 100-0.

(Image courtesy of the AlphaGo Zero blog)
The team at DeepMind describes it well:
"[AlphaGo Zero] is able to do this by using a novel form of reinforcement learning, in which AlphaGo Zero becomes its own teacher. The system starts off with a neural network that knows nothing about the game of Go. It then plays games against itself, by combining this neural network with a powerful search algorithm. As it plays, the neural network is tuned and updated to predict moves, as well as the eventual winner of the games.
"This updated neural network is then recombined with the search algorithm to create a new, stronger version of AlphaGo Zero, and the process begins again. In each iteration, the performance of the system improves by a small amount, and the quality of the self-play games increases, leading to more and more accurate neural networks and ever stronger versions of AlphaGo Zero.
"This technique is more powerful than previous versions of AlphaGo because it is no longer constrained by the limits of human knowledge. Instead, it is able to learn tabula rasa from the strongest player in the world: AlphaGo itself."
For Big Brain agentic systems, this means training the model to understand tasks and actions with reinforcement learning and that's basically what OpenAI did with Project Strawberry.
Strawberry points the way to what every lab and applied AI team will be working on over the next few years.
Again, Strawberry is a great idea, but it's not some crazy new AGI technique. The techniques behind the model comes from an old Google Deepmind technique that taught models to play Atari games with reinforcement learning in 2013.
If we look at the Q* paper, it's basically a learned deterministic policy, which means that exploration drops to zero after a time. That's good for games, as it means that the model will never just randomly go right when it's found the optimal path at a certain point is left. It also makes it good at hard reasoning, like math, or formal reasoning like logic. You want the model to learn 2 x 2 = 4 every single time, not some of the time.
What this technique can't do is capture "fuzzy reasoning," the kind of "rule of thumb" reasoning that we do. You might make an unconscious rule in your head that to check that an email was sent you need to look in the "sent" directory, but not always. On some systems, ironically our agent that checked drafts was right because of someone's poor UI design. Sometimes it might be "drafts" or something else and you adapt as needed. A good generalizing policy needs to take into account the idea of "folders" where emails that have already gone out are stored.
At Kentauros AI, we see a trajectory to advance our own autonomous GUI navigation agents and by extension every kind of open-ended task automation agent. What we're doing can be abstracted out into any agent that is trying to automate a complex task in the real world.
We choose GUI navigation because it's a much harder problem to solve than video games. The web is a vast, open system, with pitfalls, errors, problems, good design, bad design and more. It's a world of sparse rewards, where you have to click a lot of things and toggle a lot of switches to get a meaningful reward.
In other words, it's hard and what we've learned there can help anyone trying to build an agent in a more controlled environment.
While the big AI labs are promising that we'll have models that can reason easily about any task and do it with very little business integration work and training, they are dead wrong. For the foreseeable future, integrating these AI systems into the real world is the hardest problem, not to mention making them reliable, tying them into legacy systems and more.
This is not an open question.
Most people just think it's an open question.
They believe the big labs when they say the models will just be so good that there's nothing left for us to do. Those folks have a bridge to sell you and they sold it to a lot of people but it's simply not true.
OpenAI has a blueprint for its five steps to AGI:
Level 1 ("Conversational"), AI that can converse with people in a human like way
Level 2 (“Reasoners”), means systems can solve problems as well as a human with a doctorate-level education. We've seen the first stages of this with o1.
Level 3 (“Agents”) are systems that can spend several days acting on a user’s behalf.
Level 4 ("Innovators") are AI system that can develop new innovations and novel ideas.
Level 5 (“Organizations”), means an AI systems that can do the work of an entire organization, like a small or medium business
Each one of these steps is a quagmire in and of itself. Each one has a series of mini-steps, setbacks and problems that are incredibly hard to overcome, not to mention painful integration points to make it all work in any single business or to accomplish a single task.
In other words, there is friction at every one of these steps. A lot of it.
At Kentauros we see an eightfold path to better agents:
Tool interface models
Parallel processing
Memory
Shared memory
Task specific reasoning
How swappable skills
Generalized task reasoning
Generalized reasoning
We don't see these as steps.
We see this as a major road with side roads, all of those roads branching and sometimes looping back to the other roads.

(Image Midjourney 6.1)
Of course, any project will need to have an order to tackle these in, because nobody can do these all at once.
The good news is, once you go down one of these roads, it lets you start tackling other pieces of the stack. It helps you understand the task you're facing, make mistakes, adjust and then move forward with what you learned.
Getting better at any one of these keys creates a positive feedback loop.
With better memory you have better workflow/tactical data which you can now loop back into your reasoning engine.
Even better, all of these pathways will compound to help you build better agents faster.
Once you have a rock solid agentic memory platform that can store any arbitrary task structures, then it applies to all your agents in any domain. When you have better memories, that gives you better workflow data that you can leverage to train better reasoning about your specific tasks with fine tuning.
These paths will also cross-pollinate across different domains. If you're trying to build an agent that automates much of your sales funnel, many of the tools you build there will help you build a bot that excels at doing IT troubleshooting.
Of course, it doesn't mean that everything will cross-pollinate across any domain. That would take generalized reasoning and that is the domain of the mega-labs. We're not there yet.
We love that OpenAI is advancing better generalized reasoning but reasoning doesn't happen in a vacuum. Just because I can reason about math doesn't mean I can reason the perfect way to respond to an inbound lead in my sales funnel with a fuzzy understanding of who that person is and what words they might best respond to right now.
Unfortunately, that sometimes means we don't get transfer learning to a new domain. Being able to reason about how to use the Salesforce API or respond to an email doesn't necessarily translate to reasoning about how to navigate a GUI. Understanding how to reason about GUIs doesn't apply to advanced understanding of fluid dynamics or building a nuclear reactor.
This is where task specific reasoning comes into the picture.
Today's models struggle to reason about anything that's not in their training data. If they never learned to output proper bounding boxes or navigate GUIs or run through a sales automation pipeline then they will struggle.
But if you're able to collect enough task specific workflow data, you can improve both your tool manipulation models and your big brain reasoners.
But what does that all mean practically? Let's dive in and find out.
Agents in Practice

Let's talk about all this from the way we're looking to advance Robbie, our line of GUI navigating agents. Right now we've released G2 and we're moving fast towards a G3 release.
To understand where we're going, let's take a quick look at where we've been and how we go there.
Robbie G1 was primitive. It basically did a single step at a time and used some rudimentary tools like Grounding Dino to try to find bounding boxes and narrow the scope of what it was looking at on the screen.
Robbie G2 was a big step up. We pioneered a number of better heuristic tools to help the agent pick what was on screen. Almost all those advances fell into the Tool Brain domain. By giving the agent better tools, its ability to solve tasks got better because it wasn't working with broken fingers. There's nothing worse than watching an agent that knows the next step is to click on Sept 15th on the calendar but because its tools are subpar it simply can't do it.
Those tool upgrades were:
OCR positioning
Grid
Region of Interest
Our absolute favorite cheap method was OCR positioning. It's lightning fast when it works.
We use the position of OCRed text as a way to get coordinates for buttons and links with EasyOCR.
If the element on the page has text it is usually easy to find. The MLLM tells us what it is looking for with its next action description and if we find a match we can easily click it quickly without more round trips to the Big Brain in the cloud.
We talked about the grid earlier. While models are not very good at knowing precisely where to click they are good at knowing approximately where to click. They can tell you that the search button is in the middle of the page or on the lower left corner.
So we help the model do this with much better precision by layering a bunch of dots with a number over the image and asking it to pick the number closest to the thing it's looking for right now.
Honestly, it’s easier to show than to explain because it makes intuitive sense when you see it:
Its biggest downside is it's "expensive" in that it involves as many as three round trips to the cloud to talk to the Big Brain in the sky.
Our third technique is "region of interest." Region of interest is a hybrid classic computer vision and Big Brain in the cloud approach.
In essence, it involves using canny in opencv to find all the right bounding boxes and then intelligently splitting the regions so that they show entire sections without cutting off parts of the piece of the puzzle the model is looking for at the moment.
We then layer all these regions onto a grid that we call the "Jeffries Composite" and asking the model to pick the number that has the element it wants. Again, it's easier to just show you:
In Robbie G3, we've added three major additions to make Robbie smarter and faster.
Asynchronous, parallel thinking
A SOTA click model
Memory retrieval and storage
These correspond to the first three roads on our eightfold path.
Tool interface models
Parallel processing
Memory
Let's start with asynchronous, parallel thinking. An agent can only do a single task a time, but it needs to be able to think about multiple things at once and then unify its insights into its next action.
In Robbie G1/2 everything was synchronous. Although we have different parts of the brain modeled inside Robbie G2, most notably the "critic" and the "neocortex", with the critic looking at actions for mistakes and the neocortex planning actions in advance, it was all executing serially, which wasn't very effective.
In G3, only actions are synchronous but the thinking part of Robbie's brain is now asynchronous and happening in parallel.
We've created a five part model of the brain:
Strategist
Tactician
Critic
Translator
Arm
The Strategist is most closely aligned with "Big Brain" in that it tries to understand what must be done and why.
The Tactician is closest to "Little Brain" in that it tries to figure out the best sequence of actions to take and in what order.
The "Critic" checks and balances the other two, looking at potential problems.
The “Translator” is closest to “Tool Brain” as it is converting the Tactician’s sequences of actions to the low-level desktop operations, like clicking and typing.
The "Arm" executes the action after taking in all that input.
The most important part of the parallel processing is that calls can happen in parallel to our foundation model in the cloud. It uses a shared memory and any part of the "brain" can interrupt the other part, especially if it notices a state change. For instance, if one part of the brain notices that the state has changed dramatically, it can trigger a relook at next steps and then the agent might continue because it was a false positive or it might discard the actions it was about to take because those actions may no longer be relevant now that the screen changed.
The SOTA click model falls into the category of Tool Brain and better "tool interface models."
We curated three different UI datasets, cleaned them, purged low quality parts of the dataset and annotated the images both manually and with the help of LLMs. We united them into the Wave UI dataset on HuggingFace. The data includes bounding boxes, coordinates data, descriptions of what is highlighted and expectations about what should happen when you interact with that particular UI element.
We used that to fine tune a PaliGemma model that was already trained on returning bounding boxes but wasn't good at GUIs.
That gave us a much better tooling model to return bounding boxes which meant we could return more precision clicks because we can ask the model to "detect the search button" and it will usually return that button exactly and we can just click in the middle of it.
When you have better tool manipulation models it's like having more agile fingers. With more agile fingers you can type faster, twirl a baton, throw a baseball and paint a picture. With a better GUI interface model we can click on the right UI element more often.
That takes us to memory.
Memory is turning out to be the most important. Most memory systems have focused on RAG systems or just storing memories in a database of some kind. It's simply not enough to throw qdrant at the model and hope it can do something useful with that data there.
Most developers make the mistake of thinking they can just dump a bunch of knowledge into a database, define a simple retrieval mechanism and that LLM will just use that memory the way we use our own memories.
It won't.
Storing the data is only the most basic level of memory and not even the most important.
What makes our minds special is how we're constantly searching and making associations between memories. When you're talking to someone, your mind is constantly hunting for relevant information you can share. Maybe it's a song you once heard, whose lyrics are relevant to what the person is saying. Maybe it's a personal story that's close to the story someone else is sharing so you can build a closer connection by showing you've had similar experiences. Maybe it's just a fact or a figure.
It's the retrieval system that makes a good agentic memory store.
But it's also what you store.
Most of the memory projects out there are just not good for agents. They're built for chat bots. For agents you need to abstract out arbitrary task sequences in the memory and you need media storage too because agents are usually multimodal. We can already remember chat threads with our threadmem package but that's not the same as long term memory that includes the sequences of actions taken, success of failure of actions, media of steps like images or video, human feedback, AI feedback on the task and more.
Our memory system lets us generate synthetic memories by demonstrating a task in video to an agent. The system annotates that memory and we can edit that and then load it into the agent's mind to help it with tasks it's never seen before.
We can delete memories, give human feedback to the entire memory and to clusters of individual actions or tasks. We can send the memory off to various frontier models for their feedback too.

All of that lets us pull dynamically from memories at the start of tasks and during tasks. That helps the model make better decisions, both at the Big Brain and Little Brain level. With a clear set of steps, it does better tactically and it can even do better strategically.
Failed task memories are useful too because we can show an agent what not to do.
None of these happens automagically. We had to design it all in. How you store, retrieve, search and reason about memories is the key to a core agentic memory system and it must be designed carefully and thoughtfully. Dumping a bunch of data into a DB and hoping it will magically make your agent better will never work.
That takes us to G4.
G4 covers the following on the eightfold path to better agents:
Shared memory
Task specific reasoning
For G4 we're building a training ground where we can automatically QA a website. You input a URL and it generates user stories and then uses G3 to run through and do smoke tests. It lets us automate running through websites. We can take control from the agent and demonstrate how to do a task and that will generate the right coordinate data and put it all into memories.
We also get even more precision tooling at this stage. With more data we can dramatically refine our SOTA click model so that it's very accurate for any kind of GUI element. Remember, these are not steps, but branching pathways and sometimes they loop back to help out on an earlier path.
We can also take that workflow data and that lets us move into the realm of refining the mind of a Big Brain model. With better workflow data we can finally take some lessons from Richard Sutton and Reinforcement Learning.
In G4 we'll take what we call the "RL Lite" approach which is training the model with RLHF and RLAIF to make it better at understanding task based workflows for our tasks. This should help the models get much better at understanding our particular use cases and get better at thinking strategically about them because they'll have a lot more training data.
The one-two punch of better data gives both a smarter Big Brain model, Little Brain and Tool Brain because we can get better clicks, understand how to progress through a GUI and reason about how to complete open-ended tasks.
We will also scale memory, by spinning up many agents at once and letting them share and pool their memories. That means when one agent in the swarm learns something, they all learn it. We just need one breakthrough and it propagates like a beneficial mutation through the genome of a species.
That takes us to G5, which gets us
Hot swappable skills
Generalized task reasoning
Let's start with generalized task reasoning:
G5 will deliver what we call "RL strong."
We're building a gym of cloned websites so the model can experiment without breaking anything on real websites. That means we're not just doing RLHF or RLAIF, we're actually letting the agent click around various fake websites and learn a policy about how to do it from its experience.
But we're not starting randomly.
We're looking to use a method pioneered out of China, which uses an LLM as a teacher to a reward driven agent.
With this approach, the LLM dynamically sets the reward and leverages its internal world model to help the agent make its initial decisions versus just trying random actions. That dramatically speeds up the process of building a strong RL agent.
Even better is that the agent is likely to get stronger than the original LLM. It rapidly learns from the LLM and then outpaces it because it can then do its own exploration, so it ends up getting a better world model on our task than its teacher.
The student becomes the master.
It also means that we're likely to get to generalized GUI navigation and generalized GUI task reasoning in our big brain agents, because we'll have learned the more general principles of how GUIs work and how to get around them.
Now we get to hot swappable skills.
No matter what we do, even with generalized GUI reasoning, the agent will still struggle with particular GUIs, just like you might be good at chess but not Go, or good at throwing a baseball but not a football. But that's okay.
With hot swappable skills, we can fine tune a small adaptor, like a QLoRa that is specific to that workflow or task. So you might train it up on your own personal in-house application and the training is very fast because you are leveraging the model's general purpose reasoning. Or you might train it to shop on Amazon.
Agents won't be limited to what they learn on their own, like humans. They can share what they've learned.
Humans can do that too, with language and books and multimedia and Youtube. But those are lossy transfer mechanisms. I have to explain what is in my head when I'm teaching you and you have to understand it and language doesn't capture everything I've learned or experienced exactly as I experienced it or learned it, even if I'm a fantastic writer.
With AI we can directly transfer memories completely intact between systems with no loss at all.
That's very powerful.
With these fine tuned adapters, we can have the agent dynamically load an adaptor for a specific site, like Amazon and suddenly it's much better at doing tasks there. That makes skills hot swappable. We don't need a general purpose model that knows everything. If it can dynamically load adapters on the fly and suddenly it is better at that specific skill, like Neo suddenly knowing Kung Fu.
Think of a cleaning robot that downloads a new adapter on how to do the dishes or make dinner. Now it can swap in that module when it's time to make that meatball pasta for the weekend. It can download the dog walking module and learn to walk your dog instantly.
All of that means we will have very strong, very powerful agents.
That leaves us with only one road on the eightfold path.
Generalized reasoning.
To get there we will likely need algorithmic breakthroughs.
I also left out a world model and self model and other more advanced topics I talked about in my article Why LLMs are Much Smarter Than You and Much Dumber Than Your Cat. None of these are solved problems and they’ll take new algorithms, new applied AI breakthroughs, new datasets and/or new approaches altogether.
All these approaches can and will give us better models but without new breakthroughs that give us better fuzzy reasoning, common sense, abstraction and strategic thinking, we'll always be limited to what we can teach a task specific agentic system and what it can do and what kinds of mistakes it makes.
That's alright, because even if generalized reasoning takes decades, we will have very, very powerful automation engines by going through paths 1-7.
The End and the Beginning
None of this is easy.
Applied AI is taking the strengths and limitations of today's models and somehow making them work in the real world. But the real world is a messy place with sudden errors, people that cross the street when they shouldn't, friction, dust, parts that break, a sudden gust of wind that knocks your perfectly calculated trajectory off course.
Applied AI is getting your hands dirty. Anyone working in agents is trying to take these science projects out of the lab and make them work in the real world.
Along the way, we quickly find a thousand problems that seem to multiply at each step and a thousand little joyful breakthroughs too.
Building agents is hard work. We are not just going to leap to AI systems that can do anything we ask in the real world. First we need domain specific systems before we can make systems that can do anything we can throw at it. We need to learn from those domains and apply it back to a more general purpose agentic platform.
Right now in the world of AI agents, it often feels like we wanted to build a website but first we have to invent PHP, Mysql, Linux and Apache. Once we do that we can finally get around to building that website.
As the old spiritual joke goes, if you want to make a pizza, first you have to create the Universe.
In other words, you need the infrastructure to build that pizza in the first place. Without cheese making and dough making and knives and ovens and the concept of pizza-ness and you to want that pizza, there is no pizza.
But each day we're making progress. Each day we're moving forward.
And slowly but surely we're making our way to Rosie the Robot and the world will never be the same.

(Rosie the Robot character, courtesy of Warner Brothers)