Why LLMs are Much Smarter than You and Dumber than Your Cat
And What We Can Do About It - A Blueprint for AGI


These two things are true at the same time:
GPT-4/4o, Claude Sonnet 3.5 and Llama 3.1 are infinitely smarter than you.
GPT-4/4o, Claude Sonnet 3.5 and Llama 3.1 are much, much dumber than your cat.
How is that even possible?
How can we have a machine that can pass the bar exam, write code, speak 100 languages fluently and yet can't figure out new patterns, forgets what it was doing five minutes ago, and rewrites the exact same function in your code with a different name despite the other function sitting right there under its nose in the same damn file?
The answer will take us on an epic journey across the bleeding edge of modern AI, the entire multi-billion year evolution of life on this planet, and deep into that wonderful lump of grey matter in your skull, the human brain.
It's easy to get swept up in the accelerationist/doomer narrative that the Singularity is near and Artificial Super Intelligence (ASI) is just around the corner and it will give us all runaway superpowers or kill us all.
I love the systems we have today. They're limited but they're incredibly useful. They've helped me learn to code at the ripe old age of 48 and they've helped me learn A1 Spanish and they rapidly find answers to hard questions for me via RAG and search enabled LLMs. I used to use Google first for everything and now I use Perplexity 80% of the time and only do deep searches on Google when I need to crawl through results myself manually using my human common sense and intuition to find the answer.
But they're still limited.
If you work with the modern marvels of Claude Sonnet 3.5 or GPT 4o or Qwen 2 (and don't get me wrong, these little machines are marvelous) it doesn't take long for the illusion of super intelligence to wear off.
If you want to understand the limits of AI today, try to build an agent.
And I mean a real agent, one that does complex, open ended tasks in the real world, not one that fetches a few PDFs and summarizes them.
You can tell your human co-worker: "I need you to go off and put together a complete plan for outreach to our potential customers, craft a list of needed assets, setup an outreach sequence and come up with a novel way to make those interactions feel more natural rather than doing cold email outreach."
They'll figure how to do it and all the complex intermediate steps to take along the way, while asking questions or getting the help they need to get it done if they don't understand each step.
An agent will hallucinate five to twenty steps into such an open ended task and go completely off the rails.
It will never figure out the right assets or where to look. It won't figure out how to find and set up the right outreach software and craft the message based on theory of mind (aka understanding other people) and how they will respond. It will fail in countless ways big and small. It just can't do this yet. Not with today's technology and probably not with tomorrow's either.
Open ended agents are what we want and what every advanced team is working towards.
We really want digital people or digital super people working closely with us as partners and friends.
That would mean we have intelligent machines that can go out with minimal instruction and do open ended tasks, plan ahead, simulate outcomes, learn as they go and adjust in real time to ever changing circumstances in the endless variation of the real world, all while overcoming obstacles and adjusting their mental structure with an advanced neuroplasticity that models the brain, while also constantly updating their understanding of the world and how they play in it and what they did "right" or "wrong" in the ever shifting arena of life.
(Source: NICABM)
But that is not what we have today and anyone who thinks ASI is just around the corner is likely getting high on their own supply.
At best we have narrow agents that can fetch things from the web and summarize them, score them, do some outreach if the systems are already set up for them, automate parts of some tasks if those tasks are scoped down really, really tightly and compartmentalized with a lot of glue code.
My team is building agents. And every team I've talked to that's building agents has pivoted from "we'll build a general purpose agent" to building a "narrow agent" where they've drastically pruned the scope of their ambitions and surrounded a Multimodal Large Language Model (MLLM) with expert heuristics and guardrails and smaller models to compensate for the absurd reasoning of LLMs.
What do I mean by absurd reasoning?
I mean these machines completely lack basic common sense.
If you were naked and I told you to run down to the store you'd have the common sense to know you should probably put some cloths on, even though I never explicitly told you that.
Here's another example from Max Bennett's amazing book A Brief History of Intelligence. I started with the line "He threw a baseball 100 feet above my head, I reached up to catch it, jumped..." and let it finish the sentence.

Because of your common sense, you'd know the ball was too high to catch.
GPT-4o does not know that.
Don't get me wrong. Many of these systems are still good and useful and they do things that simply weren't possible a few years ago.
I wrote one knowledge assistant that went out and crawled 30K websites of potential partners and the bot summarized what they do, found their current pricing and scored them according to a hand crafted selection criteria in a function call. It saved our team a massive amount of time. It would have taken us months to go read all those sites manually.
But it also sucked too.
It was like playing edge case whack-a-mole. It was not easy to get right and it took about a month of hacking away and adding checks and balances and prompt engineering to make it work.
That's still a far cry from just talking to a super smart machine and giving it the broad strokes of what you want and having it go out and figure out the whole task on its own and do it effectively with minimal supervision, checking in every few hours or days with questions, followups and adjustments.
This is not "Her."
Every single agent today is a bespoke work of art, a beautiful little snowflake that some team slaved over for months to get working. They're hand crafted marvels of overlapping traditional AI methods, prompt engineering, creative thinking, hand written code, hacks, heuristics, and chewing gum to hold it all together.
And no GPT-5 or Claude 4 are not just going to "solve everything."
They won't.
Neither is GPT 6 or Ilya Sutskever's SSI and its "straight shot to superintelligence."
And that's because AI today is missing some fundamental things.
The longer you work in AI the more the glaring reality sets in as you realize:
The human mind is still a massive mystery. We really do not understand how we do what we do.
The human mind is highly advanced and evolved over a LONG time in evolutionarily robust layers that abstract and feed off of the layers below into a complex synthesis of robust and adaptable decision making.
We've managed to make some very useful algorithms that approximate parts of intelligence but we have zero insight into many other parts of our intelligence and those holes are painfully obvious as you try to get these systems to work reliably.
What's even more frustrating about this is that it often feels like we are so, so close.
In many ways, we already have superhuman machines. They're not coming tomorrow. They're here. How many people do you know that can speak 100 or a 1000 languages fluently and pass the bar exam and be your doctor and your writing coach and code up an app for you at the same time?
But the more you look at what's missing the more you realize how far away we are.
An article from Forbes in 2016 was called "Google Masters the First 90% of Driving: The Last 10% is the Hardest."
We're still waiting to master that "last 10%" and it might as well be 80%.
AI Cats on a Hot Tin Roof
So what's missing?
Yann LeCun, head of AI at Meta, is fond of saying "we don't even have cat level intelligence."
I've often thought the same but I couldn't put my finger on exactly why until very recently and it all came together for me when I read Bennett's brilliant "A Brief History of Intelligence."
You will see me quote a lot from this incredible book here because I don't know that I've ever read a better synthesis of the history of neuroscience and AI. If you haven't read it and you work in AI you should go and get it immediately.
The key to understanding what Yann means by "cat level intelligence" is perfectly encapsulated in this little nugget from the book:
"The [human] brain...somehow recognizes patterns without supervision, somehow accurately discriminates overlapping patterns and generalizes patterns to new experiences, somehow continually learns patterns without suffering from catastrophic forgetting, and somehow recognizes patterns despite large variances in its input."
There's a massive gap between our brains and today's systems. And it gets worse because there's even more missing.
Let's take a look at just a few of the unsolved problems in machine learning that way too many folks think we'll solve by magically hurling more data and GPUs at the problem:
There is no frontier model today that can bootstrap itself unsupervised from nothing, learning whatever it needs to learn through experience and experimentation, outside of narrow game playing systems like AlphaGo Zero which have a finite, fixed goal that is easy to define.
Give a system an open ended goal like "who am I and what should I do in the world" and you will get absolutely nowhere.
No model today has an effective "world model" of the outside world or an internal "self model" that can imagine itself as an actor in the world and play out scenarios ahead of time before making a decision, thereby eliminating possibilities via simulation.
If you teach any model new things with fine-tuning, it forgets some old things, aka it's subject to catastrophic forgetting, where some of its weights get overwritten with new information causing it to forget what it knew before.
Adaptors, which freeze the weights of the model and add a smaller file with new weights, solve part of the problem but not all of it.
No model today can continually learn new things. When you talk with GPT is it not learning from that experience and changing its mind and updating its sense of self and its understanding of you and the world around it. It can only learn when it is explicitly being trained, while offline, not online and in real time.
Your brain is very adjustable. It creates new connections and prune old ones constantly, updating the very hardware of your mind with new concepts and abstractions from its experience.
An AI model is basically frozen in time at its last training date.
There is hope on the last three. A massive mixture of experts model might solve catastrophic forgetting and continual learning and neuroplasticity though (more on that later.) But there are still other major unsolved problems in the space.
Today's top models can't recognize new patterns and invent novel solutions. You might show a model a million different rockets and get a rocket variation from it but you won't get it to design a rocket when it previously did not exist. It will not design a fusion reactor because we don't have them yet and it can't come up with how you would build them.
Humans, on the other hand, can conceive of a rocket, by abstracting old patterns/concepts and applying them to a fresh problem. Then they can design it and land it on the moon on the very first try.
Speaking of abstraction, these systems can't abstract patterns and apply them to a new domain or a completely different experience. This is crucially, crucially important and it's at the heart of why LLMs are so maddeningly dumb at times.
If you get cut by a knife one time, you extract the concept of "pain" and "sharpness" and cluster that with previous concepts like "danger". You don't need to see 10,000 examples of jagged rocks or spears to know they are sharp and will cut you too. You just know, after one bad experience and you abstract that understanding to similar things easily and automatically.
Models also suck at representing/understanding highly variable inputs. Today they need lots of examples of something to recognize variance and see them as the same thing.
A convolutional neural net (CNNs) needs to see pictures of people from the side and the front and the back or it has no idea this is the same concept (a person) and should be grouped together.
Meanwhile as fish knows this automatically (and so do you). You can show a fish a picture of a frog and train it to get food if it touches that picture. Now give the fish a new picture of the frog at a different angle and it will instantly know that it's still a frog and swim right up to it to get that food.
An experiment in 2022 by comparative psychologist Caroline DeLong at Rochester Institute of Technology did the above experiment with goldfish:
"Amazingly, the fish swam right up to the new frog picture, clearly able to immediately recognize the frog despite the new angle." writes Bennet.
By contrast, people, monkeys, gorillas, fish and cats are certified geniuses versus GPT and Sonnet when it comes to all of these things:
We can easily recognize new patterns we've never had any exposure to without any supervision whatsoever.
We also figure out which pattern is which when we have a lot of overlapping patterns and we effortlessly filter out the noise that's not relevant to the pattern.
We learn continually, without forgetting old concepts and ideas (well some people do at least).
Finally, we recognize objects and concepts despite tremendous variance instantly. We even have a built in understanding of 3D objects. You understand what a cup looks like from all sides after seeing just one side.
Humans have a few other tricks too:
We generalize any pattern to new experiences.
Even better, we abstract concepts from one domain and apply them to entirely new ones that are seemingly unrelated on the surface.
We can transfer and accumulate knowledge over time with writing and language and we can build on the information of the past.
We hunker down and work at something based on a far away reward, like learning a language, because we can simulate ourselves into the future and imagine the rewards of being able to talk to people in that language and thereby maintain our goal over long periods despite little to no short term benefit.
All that points to one thing and one thing only:
We need new algorithms in AI to get us to the next level.
What kind exactly? Let's dive in and have a look.
The Missing Link
Let's start with some of the more innovative thinkers in AI/ML who already understand that we need something new, versus the folks who think we will just throw more GPUs at MLLMs and get superintelligence.
We won't get superintelligence that way, though we will get some cool new emergent properties that are very useful as we scale up the size and data of these massive machines, just not everything we really want from intelligent machines.
So what do we need to do?
We'll start with Yann LeCun, who probably has the most advanced proposal for next-gen systems.
In LeCun’s own words:
"We humans give way too much importance to language and symbols as the substrate of intelligence. Primates, dogs, cats, crows, parrots, octopi, and many other animals don’t have human-like languages, yet exhibit intelligent behavior beyond that of our best AI systems. What they do have is an ability to learn powerful “world models” that allow them to predict the consequences of their actions and to search for and plan actions to achieve a goal. The ability to learn such world models is what’s missing from AI systems today."
Bennett, Max. A Brief History of Intelligence: Evolution, AI, and the Five Breakthroughs That Made Our Brains (pp. 185-186). HarperCollins. Kindle Edition.
World models and high sensory inputs, not just text, are at the heart of LeCun's proposal for better and more advanced AI that more closely models the human brain, which you can see in this elegant diagram of his working hypothesis for how these systems might work.
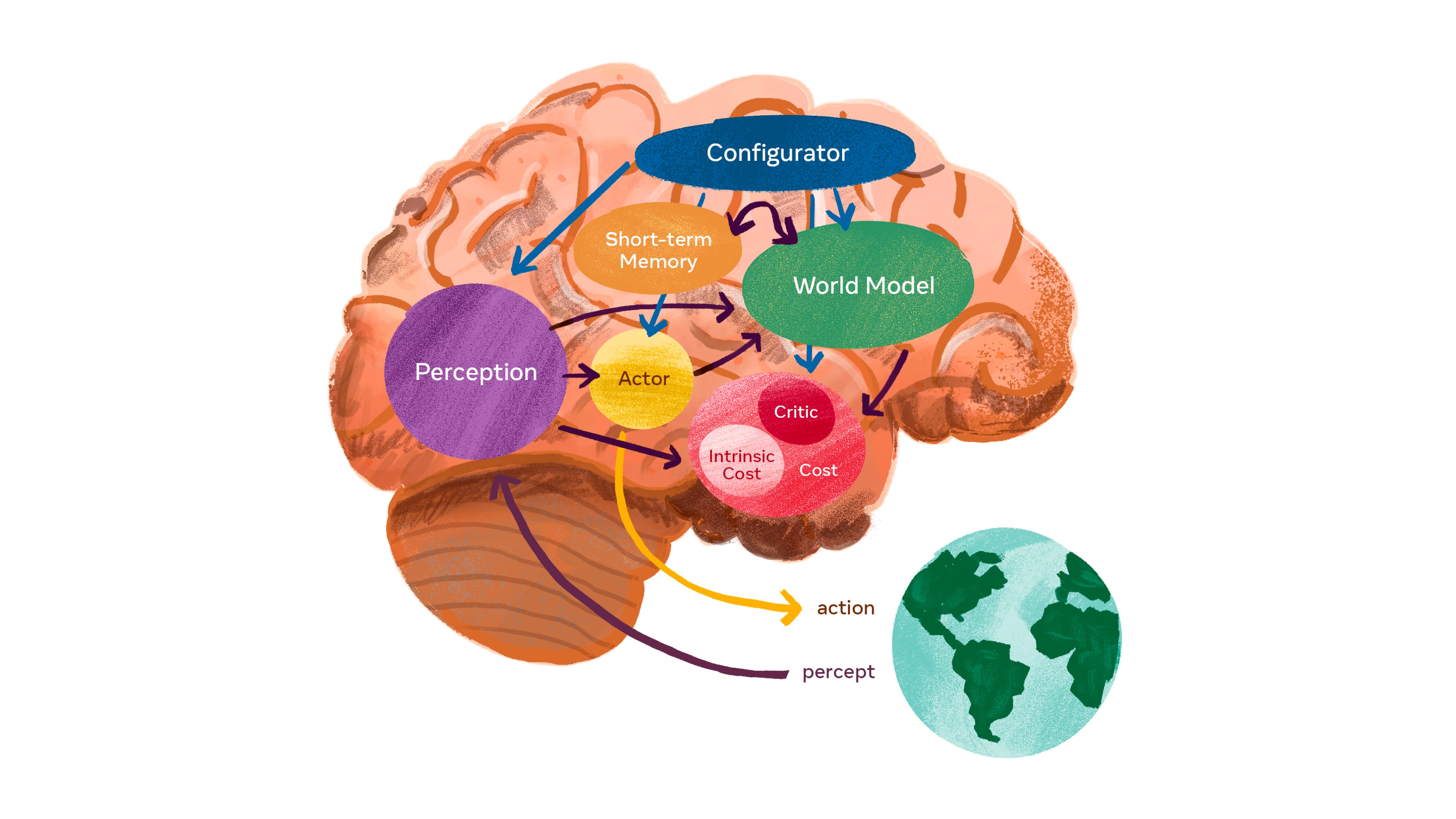
It's very similar to the architecture that we've stumbled upon as we work on agents at my small lab at Kentauros AI. We created an actor/critic and neocortex for simulating next steps with Robbie, our Gen 2 agent, and wired it to text and image perception and the next phase is to add long and short term memory and pattern prediction.
To be clear, our solution is a short term applied AI hack, not a fundamental new neural network architecture, but we did get some strong results simply by doing what humans do best:
Making things work with new and creative approaches
Repurposing old concepts in new ways
Our aspirational architecture shares a lot with LeCun's team's ideas but adds some additional wrinkles too. I have little doubt that if his team pulls it off, it will be a truly next-gen system that is incredibly useful and a radical departure from what we have today. Hopefully we will even get a successor to Llama 3.1 from his team.
But I also think there is a next step after that and that's what I spend nearly every waking second of my life thinking about these days.
Where we diverge is that it's probably not enough to have a "world model" of everything "out there," meaning a model of everything outside of you and happening around you. You likely also need to have a "self model" that models "in here," aka an internal model of you that lets you simulate yourself and who you are and your own actions and how they will interact with the outside world.
Here's a WIP architecture that needs to be dramatically simplified but gives a sense of what it might look like below the surface.

Evidence for this kind of architecture is all over our brains and we draw our inspiration from neuroscience research, our own experiments, and ideas from books like A Brief History of Intelligence, and A Thousand Brains by neuroscientist and AI researcher Jeff Hawkins.
We're simulating and predicting and projecting ourselves out into the world and imagining responses and reactions before we take actions. It's a constant push pull with reality, as we update our internal understanding of the world through trial and error.
But how do we do that?
You'd think that we have a ton of sensory neurons in our brains and a bunch of predictor neurons that are seperate from those. But that's not how it works. In the words of Jeff Hawkins:
"First, given that the neocortex is making a massive number of predictions at every moment, we would expect to find a large number of prediction neurons. So far, that hasn’t been observed."
Hawkins, Jeff. A Thousand Brains: A New Theory of Intelligence (p. 58). Basic Books. Kindle Edition.
So how does it work?
Take the neurons that are wired to your eyes, ears, nose, etc. The very same neurons that process input from your eyes also light up when you're imagining what you see or daydreaming about it or thinking about it.
Think about that for a minute. It means we have a generative model in our heads and it runs on the same neurons that also process those sensory inputs.
When you're daydreaming or thinking strategically, when you're trying to do complex movements, when you're actively learning, practicing guitar, watching someone else do a complex action or trying to figure out what other people are doing and why, the very same neurons that process smell, touch, visual and auditory inputs are lighting up.
According to Bennett: "People with neocortical damage that impairs certain sensor data (such as being unable to recognize objects on the left side of the visual field) become equally impaired at simply imagining features of that same sensory data (they struggle even to imagine things in the left visual field)."
Bennett, Max. A Brief History of Intelligence: Evolution, AI, and the Five Breakthroughs That Made Our Brains (p. 183). HarperCollins. Kindle Edition.
None of this is obvious or expected. We could easily have evolved seperate parts of our brain for imagination versus sensory input. But instead, they happen in the exact same spots.
Seeing/hearing/tasting/smelling/touching are inextricably linked to imagining those things, or as Bennett says, they're "two sides of the same coin."
But it goes much deeper than that. There's the old philosophical question of whether we live in a simulation. I don't know about an "out there" simulation but if you look at the brain and how it's wired:
We do live in a simulation.
It's just inside our heads.
We simulate our next complex movements a split second before doing them. We imagine the meaning behind the actions of others. We simulate our sense of self and our reasons for doing things. Who am I? Why did I do that? What do other people think of me? Why is she looking at me like that? What did he mean by that? We manufacture our intent our sense of self.
Our brains are rehearsing, projecting, visualizing and making predictions constantly. And it all happens at an unconscious level millions or billions of times a day. We're not even aware of it most of the time. Even better, it happens right in an area about the size of a dinner napkin, if you stretched it out and ironed it, the neocortex.
But how do our brains makes those predictions?
When our neurons are anticipating the next step in a pattern they know, they get primed to fire but they don't fire yet. This was initially confusing to scientists. Neurons are either inactive or firing. They "spike" or don't spike. They're very binary in that way. On or off. So why send a signal that gets the neuron almost ready to fire? It's like a tease. It never quite gets there. That's not binary at all. It's almost ternary, a third state of uncertainty or in-between.
Turns out, those neurons are the ones making predictions.
"When the pattern of activity is detected...[the predicting neuron]...is...primed to spike...If a neuron in a predictive state subsequently gets enough proximal input to create an action potential spike, then the cell spikes a little bit sooner than it would have if the neuron was not in a predictive state.”
That's a mouthful so let's break it down with an analogy.
Hawkins equates it to runners in the race. The primed neuron gets off the block first if it gets the hit it was expecting as reality matches its predictions. Since it's primed, it fires faster than the other runner neurons around it because it already has a built-up electrical charge pulsing through it and so it takes off much faster and the others give up the race because it was right and they were wrong.
Neurons are constantly predicting, simulating and competing like this. They recognize patterns and try to figure out what to do next in a complex electrochemical dance, working collectively to understand the world around us.
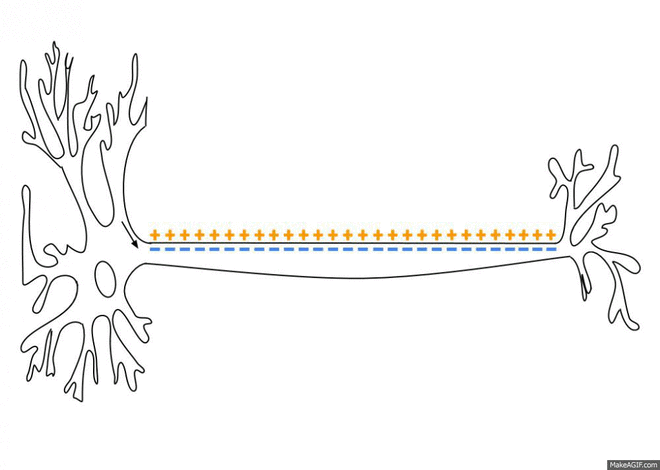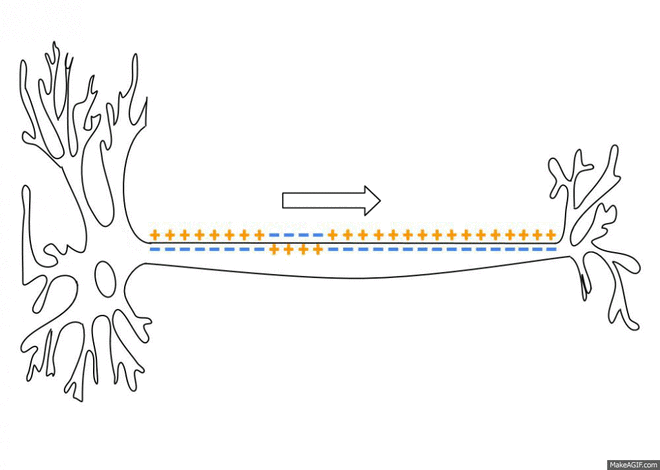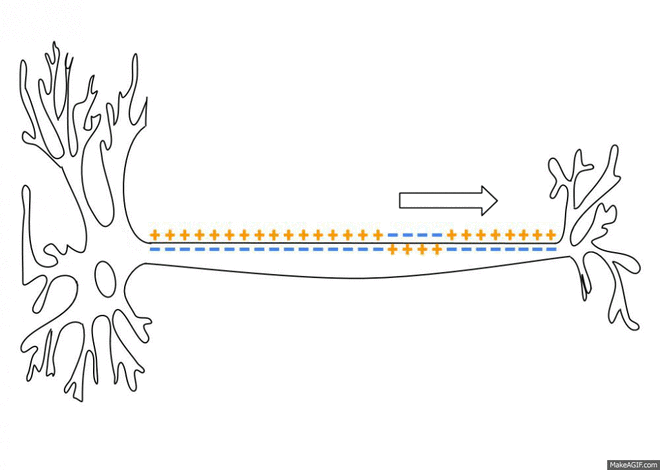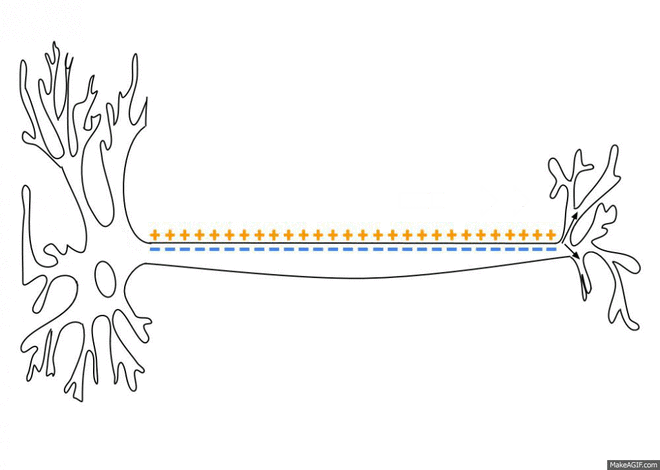
{From Wikipedia and Wikimedia Commons: As an action potential (nerve impulse) travels down an axon there is a change in electric polarity across the membrane of the axon. In response to a signal from another neuron, sodium- (Na+) and potassium- (K+)–gated ion channels open and close as the membrane reaches its threshold potential. Na+ channels open at the beginning of the action potential, and Na+ moves into the axon, causing depolarization. Repolarization (reverse the polarity!) occurs when K+ channels open and K+ moves out of the axon, creating a change in electric polarity between the outside of the cell and the inside. The impulse travels down the axon in one direction only, to the axon terminal where it signals other neurons.}
The neocortex of the human brain takes up 70% of the space in our skulls, and humans basically simulate and predict everything all the time.
Damage the motor cortex part and a human can't do anything. No basic movements and no advanced movements.
Damage the part of the neocortex that generates your sense of self, aka the part of yourself that imagines who you are and why you do the things you do and you won't recognize yourself in the mirror.
Not figuratively. Literally.
People will look at themselves in the mirror and swear that is someone else.
Without your self model you are in big trouble.
You lose their sense of purpose and intent. You lose their sense of the story of who you are and it's difficult for you to generate purpose and meaning.
Why?
Because who you are is all made up in your head. "You" do not exist in any meaningful sense. You are a made up story in your brain.
The granular prefrontal cortex (pPFC) is wired to the older part of your brain, your agranular prefrontal cortex (aPFC), and it watches your actions and abstracts meaning. The lower part of your brain might be saying, "eat now" or "want food", simple brute force commands. And the newer part of your brain is generating meaning for those actions, like "I'm going to go make dinner because I'm hungry now."
Even better it can predict when it will be hungry later and take action before you're hungry. It might give a directive to the lower brain and say "I'll be hungry later so I should get started on dinner now because I don't want to be hungry and also I feel like making pizza because pizza tastes great and we haven't had it in ages."
This might not happen in language. Some people don't think with an internal voice, which is called anaduralia. Others like me do have an internal voice, or set of voices, that are chatting and acting like a movie voiceover to my life all the time.
But no matter what, we're always planning and simulating ahead whether that's visually or with thoughts that "bubble up" from the void or with a chorus of voices in our head.
And you're not just simulating your sense of self and the world out there when you're navigating your bedroom in the dark to go pee. Most of the time your brain is completely simulating the external experience once it has learned the patterns and barely processing what is happening outside of you at only the most minimal level.
It's pattern matching and filtering out the vast majority of the information.
Talking walking as a good example. Once you learn how to walk, the neurons that sense touch on your feet, simulate those sensations as you walk. Only if there's a mismatch in the prediction, like you suddenly step in shit or the ground is not there, do you "wake up" and experience the outside world.
The reasons for this are likely very simple. Processing external inputs is hugely expensive energy wise and exhausting. If my sensory inputs dramatically scale down the detail/resolution of external input, taking in only something like 5% or 10% of it, it's much less energy intensive.
How often have you traveled or gone to a concert or some new experience with lots of sights and sounds and wound up incredibly tired afterwards? That's because you're forcing the brain to process all of that external input in high detail because it's never seen it before and it can't simply generate a model of it. Simulating the outside, while only paying minimal attention to check for unexpected changes like a squishy feeling under your feet instead of the predicted thud of concrete, is much more cost effective for your brain.
That's why walking around you neighborhood is not nearly as tiring as going to a museum or a concert. Your brain has memorized all the patterns of your neighborhood and now you only experience them in the virtual reality of your mind most of the time.
We create and constantly update our idea of ourselves and the world. We create our intent and desires and simulate not just what is out there but how we play in it, imagining ourself doing things and creating our sense of self as we go and infusing it with what it means to be us as we experience the world and take actions in it and reincorporate that feedback.
We're not the only ones. When monkeys watch other monkeys doing stuff in the world, the parts of the brain that light up are the same that would light up if they were doing those actions themselves and the higher part of their brain is asking questions like "why would I do this and what does it mean?" in whatever way monkeys visualize ideas or experience thoughts.
Our ability to understand ourself is directly tied into our ability to simulate others and what there intentions are, which we call "theory of mind." We understand what others are doing through the lens of why we do it.
Again the evidence for this is right in our grey matter and in neuroscience experiments over the past few decades which have dramatically increased our understanding of the brain.
According to Bennett: "In 2015, scientists did the following study. They gave participants a neutral cue word (e.g., bird or restaurant) and asked them to tell the experimenter different narratives of themselves associated with that word. Some of these participants were healthy, some had damage to areas of the granular prefrontal cortex, and some had damage to the hippocampus. How did people’s narratives differ across these conditions?
Humans with damage to the granular prefrontal areas but with the aPFC and hippocampus intact were able to imagine complex scenes, rich with detail, but they were impaired at imagining themselves in such scenes. They sometimes even completely omitted themselves from their narratives.
Damage to the hippocampus seemed to have the opposite effect—patients could imagine themselves in past or future situations just fine but struggled to build external features of the world; they were unable to describe in detail any of the surrounding elements."
Again, this suggests that different parts of the neocortex build a world model of "out there" while also building a world model "in here" and then update them together in real time as circumstances and new experience comes in.
There is no evidence that rats or other non-human primates are creating any meaningful representation of themselves though. This seems to be a very human or ape like evolution of the brain. The self model is special and essential to comprehensive, primate level intelligence.
But rats do simulate out there, aka a world model, and many other animals too. If you damage the motor cortex in the neocortex of rats, the rat can still hunt, fight, eat and run, because the older and more primitive parts of their brain still remember. In other words, it can do previously memorized movements.
What it can't do is learn new complex movements and it can't simulate the outside world and plan or predict its moves in advance.
In lab tests, if a rat comes to a fork in the maze, it starts nodding its head back and forth as it simulates the outcomes of going one way or the other. Damage the neocortex of that rat and it stops that head nodding.
Why?
Because it needs to imagine those movements as it's doing them. Because that part of the brain is damaged the rat can no longer see ahead to potential outcomes and just moves on basic instincts. It picks left or right quickly and hustles along.
The simulation aspects of our mind go even further though and it even gets a bit weird from here.
To quote Bennett once more: "The idea that the new primate areas take part in modeling your own mind makes sense when you follow their input/output connectivity. The older mammalian aPFC gets input directly from the amygdala and hippocampus, while the new primate gPFC receives almost no amygdala or hippocampal input or any direct sensory input at all. Instead, the primate gPFC gets most of its input directly from the older aPFC."
Read that again.
The newest evolutionary addition to the primate brain, the gPFC does not get any sensory input at all.
It is an abstraction layer.
It sits on top of the parts of the brain that came earlier in evolution, like the amygdala, the part that recognizes patterns across varying modalities and makes predictions about those patterns and where our "emotions" potentially live, and the hippocampus where we store spatial maps, short term memories and where we process those memories for long term storage.
One way to interpret this is that the newer parts of the brain, like the granular prefrontal cortex, create explanations and intent and meaning about our actions and the outside world, as it feeds from the older part of the brain the agranular prefrontal cortex, in essence creating our sense of what we would call "mind."
An abstraction on top of an abstraction.
A simulation of a simulation.
It is simulations all the way down.
A Blueprint for AGI
So how will we likely build AGI? How can we recognize it when it gets here?
AGI is almost certainly a tangled mess of systems architecture, machine learning with ideas borrowed from lots of other places like neurochemistry, neuroanatomy, traditional programming, systems thinking and much, much more.
What you'll read below is a mashup from a thousand different disciplines and ideas but its grounded in the latest papers in machine learning and in historical ones too.
To me the core components of an AGI system are:
World models/Self models
Object oriented learning/thinking
Prediction/simulation
Experiential/unsupervised learning
Downloadable/sharable/translatable weights
Model merging/model evolution
Associative memory and register based memory in one
Continual learning
Mass parallelization
General purpose algorithms
We've talked a lot about self models and world models. But to succinctly summarize:
World models are learnable/updatable models of the external world, aka anything outside of ourselves or our AI agent
Self models are learnable/updatable sets of beliefs and understandings about the self as an actor and how we fit into the world and act in relation to the world.
In essence a self model is a set of belief structures and values that the model holds about who it is and what it believes and how it acts in the world.
It's a policy gradient and a senses simulator and a story creator all rolled into one.
The world model is primarily a spatial/object centered view/map of what's out there.
What do I mean by object oriented?
Let's take a deeper look at that first.
Then we'll walk through some of the other practical ways to move AGI forward, with actual, concrete steps we can take in system architecture with real world prototype algorithms and techniques we have today that will likely lead to the systems we really want in the future.
We'll also look at some things where we just don't have a solution yet but where the solution is possible to look at in the abstract and helps us understand what the solution will likely look like and what properties it will need to have it work well.
The Objective View is Subjective
We don't understand the world directly. We learn a model of the world. That model is never the complete picture and can't possibly encapsulate all of reality. At best it can only be a small sliver of reality or an approximation of reality.
Think of it as a map versus the territory. The territory is not the map but the map helps us get around the territory.
But how do we built that model/map?
You me and every other creature are object oriented. That's how we see the world and that's how our world and self model gets built and maintained and updated.
Object oriented programming didn't come out of thin air. It was responsible for a revolution in modern programming and that's because it intuitively modeled the primary structure of how we learn and see the world.
You can check out a great refresher on object oriented programming here at the Spiceworks blog. But most of the key ideas are right here in this great little graphic:
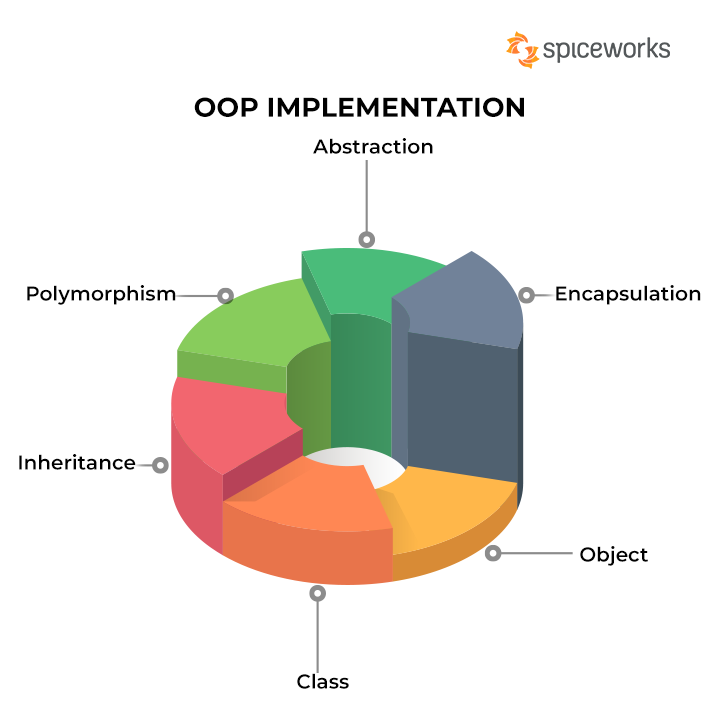
(Courtesy of the Spiceworks blog on OOP)
Let's do a thought experiment for a minute:
Imagine that you've seen a coffee cup in your lifetime and you've seen a drawing of a superhero in a comic book but for some reason you've never seen seen the two things combined. Then one day you see a coffee cup emblazoned with an image of superman on the side.
Why are you not thrown off by the novel combination that you've never seen?
Because your brain inherently understands the class of the two objects, their inherent properties and how they associate and combine to form something new. Your brain intuitively recognizes the cascading set of patterns that make up the objects in the world around us:
Object: Container -> Cup -> External/internal surface of cup
Object: Flat plane -> 2D image representation of 3D -> Image
Flat object wraps 3D container object
Concepts are objects too and your mind also intuitively understands the abstract concept of "combinable/transferable/writable" which the cup external surface has and the image also shares as well.
Put more simply, we intuitively understand how things go together and combine.
AI researchers have been working on some form of object oriented ontology of a world model for decades, going back to the expert systems days. While we've largely abandoned these ideas in modern AI, we should not be so quick. There is always much to learn from the past even if those ideas didn't work perfectly in the past.
Maybe we just weren't ready for the idea or it was incomplete or to really make it work we needed other things to come into existence.
Perhaps the biggest problem was that a world model was hand programmed by early AI researchers. They'd start by trying to hand write a set of rules for all knowledge. So they'd write the characteristics of a cat and then realize they needed to define what a cat was, but the only way to define a cat was to define it by its characteristics so they quickly got into a circular reasoning loop.
The key to a successful world model will be a learnable/generalizable world model.
By learnable/generalizable I mean the Bitter Lesson of Richard Sutton:
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin."
Most folks think that Sutton just meant scale is king, aka GPUs go burr but it's a bad misreading of what he said. Later in the same post he writes a strong clarification:
"AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning."
AGI will not be a system where researchers painstakingly lay out every property of reality and how they relate to each other.
Instead they'll deduce the base level primitives and then let the generalizable world model algorithm learn how to classify things into that ontology and scale it.
The example of the power of pure learning and search is illustrated perfectly by the the evolution of AlphaGo to AlphaGo Zero.
Most folks know the story of AlphaGo and how it beat Lee Sedol, the best player in the world 4-1 but they don't know the story of AlphaGo Zero.
AlphaGo was a supervised learning and exploration system. It learned policies from human games and it had a lot of expert logic tuned into it over time. It was an incredible system. But what came after it was more incredible.
AlphaGo Zero had only the basic rules of Go to start from and then it played itself over time, spawning new versions of itself and evolving its understanding through experience and trial and error. It had no human games to learn from or advanced expert characteristics lovingly woven in by its creators.
After only 3 days of training, AlphaGo Zero smashed AlphaGo in head to head competition 100-0.
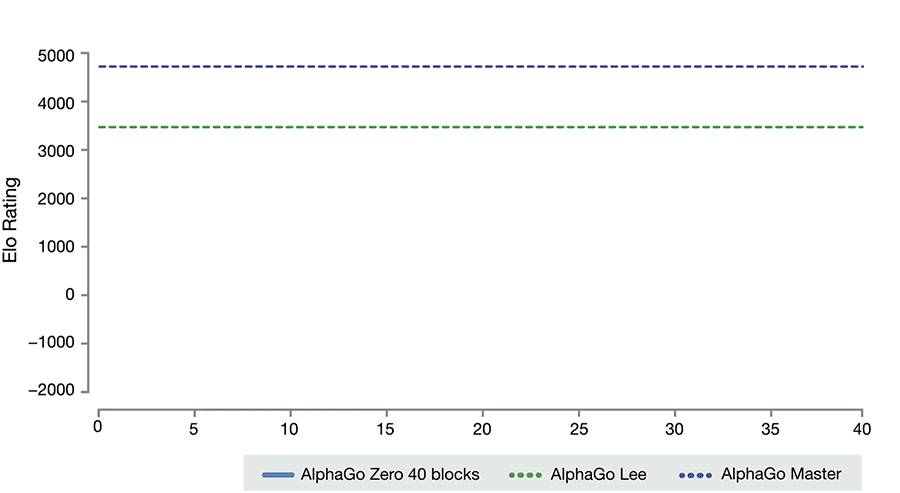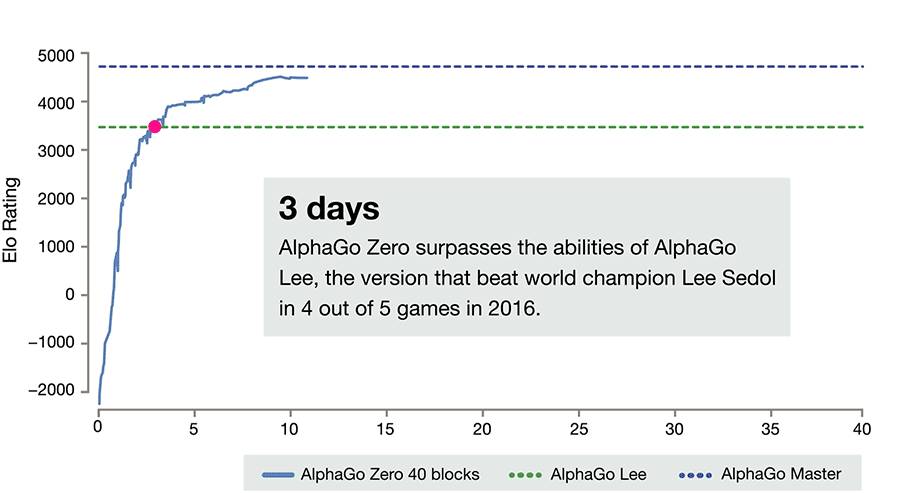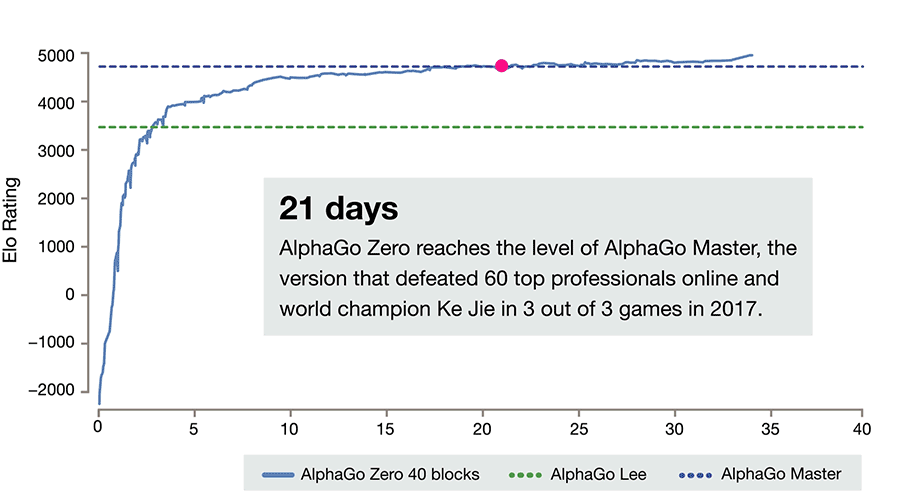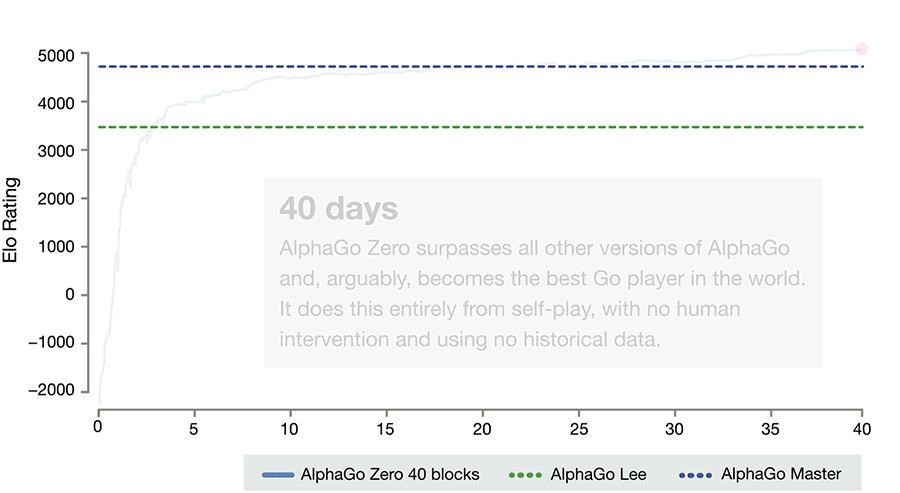
(Image courtesy of the AlphaGo Zero blog)
The team at DeepMind describes it well:
"[AlphaGo Zero] is able to do this by using a novel form of reinforcement learning, in which AlphaGo Zero becomes its own teacher. The system starts off with a neural network that knows nothing about the game of Go. It then plays games against itself, by combining this neural network with a powerful search algorithm. As it plays, the neural network is tuned and updated to predict moves, as well as the eventual winner of the games.
"This updated neural network is then recombined with the search algorithm to create a new, stronger version of AlphaGo Zero, and the process begins again. In each iteration, the performance of the system improves by a small amount, and the quality of the self-play games increases, leading to more and more accurate neural networks and ever stronger versions of AlphaGo Zero.
"This technique is more powerful than previous versions of AlphaGo because it is no longer constrained by the limits of human knowledge. Instead, it is able to learn tabula rasa from the strongest player in the world: AlphaGo itself."
I see the same thing happening with world model/self models. The system will get the base level characteristics/primitives of reality and it will automatically add to those buckets as it learns through experience, classifying its knowledge via a general purpose world model classifier into buckets that help it understand the world and itself and how it acts in the world. That system will naturally include inheritance, encapsulation, polymorphism, association, aggregation and cohesion. It will most likely be a low level set of primitives like self/actor and object which cascades to self object and external world objects, etc.
The basics of a world model ontology where already worked out in the 1980s and 90s by researchers so researchers won't have to look to far if they want to get working on it:
In the world there are several base level objects that cascade:
Objects themselves
Spaces: which contain objects
Spaces are:
Infinite or finite
If infinite they are discarded as a meaningful characteristic as they, for all intents and purposes, "go on forever" in every direction
If finite they are objects themselves
The "world" space
Which contains:
External objects like coffee cups and other people
Self: which is also an object
Internal self objects like values/beliefs/images/memories are subset objects of self
The Handbook of Statistic Vol 49 sums up the basics well:
"An object is the highest level of abstraction from a software system point of view, of literally, any concept. Even beyond software, there cannot be any concept that cannot be expressed as an object in human understanding of the world itself. Consider an example sentence, Person-A walks from Place-B to Place-C.
"In this sentence, what are the objects?
"It is easy to see noun forms as objects such as person and place. However, there is an implicit object here, walks, which is a verb. It is not at all easy or trivial to think of verb as an object. The process of object-oriented thinking helps think of a verb as an object; in this case, it is walkable. The -able suffix to verbs resulting in 〈verb〉-able form of objects."
Artificial Intelligence (ISSN) . Elsevier Science. Kindle Edition.
As Yann LeCun and other researchers have already figured out, a world model is the key to unlocking planning and reasoning agents that can take meaningful actions in the world, remember what they did and learn from it.
This should also help fill in some of the common sense reasoning issues we see with models today. What is common sense really?
Common sense is really about filling in missing steps or missing parts of a pattern that were only implicit.
Common sense is understanding complete patterns and being able to fill them in even when they appear partially or obscured or at a different angle or in a different context.
A strong self and world model, grounding in object orienting, will enable artificial minds to fill in those common sense gaps much more easily, making them true reasoners and planners.
And that takes us to the next major parts of the blueprint for AGI:
Associative and register based memory
Downloadable/sharable/translatable weights
Model merging/mode evolution
The Persistence of Memory and Trading Minds
AGI will have several other major advantages that biological minds don't currently have.
They can share parts of their mind directly.
They can store memories as both associate clusters and use register based memory too.
Let's look at these advantages in turn.
One of the basic theories of why humans have language capabilities (and no other creature seems to have it) is for sharing knowledge. Language lets us take internal thoughts and make them external. It lets us pass down knowledge through history and that lets us build on the ideas of the past. If every person has to relearn everything from scratch, we never evolve.
You can't make a microchip or a house or a pork chop without building on the ideas, knowledge and inventions of the past.
We truly stand on the shoulders of giants.
Language is our way of sharing that knowledge and it's a wonderful tool.
But it's got some problems. Namely, it's lossy. It loses parts of the concept or the feelings and experiences behind it.
Artificial minds will have no such constraints. They will be able to share shards of themselves or merge their minds with other minds directly. They could even collectively pool their minds.
Imagine that I have a million or billion models learning how to drive cars. They can share when they learn to a massively centralized model or a massive, distributed weights cluster. Every one of the cars can now learn from the shared experience of other self-driving cars as they navigate the mean streets of the world.
This "mind sharing" can also be done through simpler techniques, such as sharing loadable Adapters, which are add-on weights for a model like QLoRAs, or through model merging, or through evolutionary combination of models.
That means they can directly share and update parts of their mind.
Your house robot might know how how to do the dishes and fold laundry and if you want it to walk your dog, it can just download an Adaptor or integrate a shard of weights into its mind directly and now it knows how to walk the dog too with no lossiness.
The second one we talked about above is memory. Machine minds can easily have two kinds of memory, register based, which is how computers remember things and associative/cluster based which is how humans and animals remember things.
Our memories are pretty magical. To date, nobody has ever found a limitation on the amount of information and events and experiences we can store in our minds. Our memory is effectively, infinite. Our brains cluster together similar patterns into bundles of overlapping information. That's why memory champions use techniques like the Loci, detailed in the fantastic book Moonwalking with Einstein, about a journalist who trained his memory to compete in national memory competitions. Many of the techniques detailed in the book take unique advantage of how we remember things, like the memory palace technique where you create crazy images for things and place them in your house or your street.
How does it work?
Humans are remarkably good at remembering places. If you close your eyes you can easily navigate through your house in your mind's eye and through probably twenty other places from your past easily, like your childhood house, or grade school. Memory champs will put crazy images that remind them of key things into the house and then walk through it in their mind to remember those key pieces of information.
It works because it builds on our associative memory and spatial awareness.
But our memories are also faulty. The downside of associative memory is that it sometimes combines things or filters parts of our memory out. Even worse, it's not always accessible. Your brain may be able to store everything you've ever seen, done, or experienced but whether you can retrieve that memory on the fly is not guaranteed.
The advantage of associative memory is that it compresses a lot of a patterns together, which helps with abstracting those patterns so they can apply to new and novel situations. It also means that it can distribute the memory across the brain, which makes it more resilient. You're a multiprocessing powerhouse and the roughly 2-4 billion cortical columns in your neocortex can each store partial models of thousands or millions of objects and then share that information and come to a consensus on its characteristics.
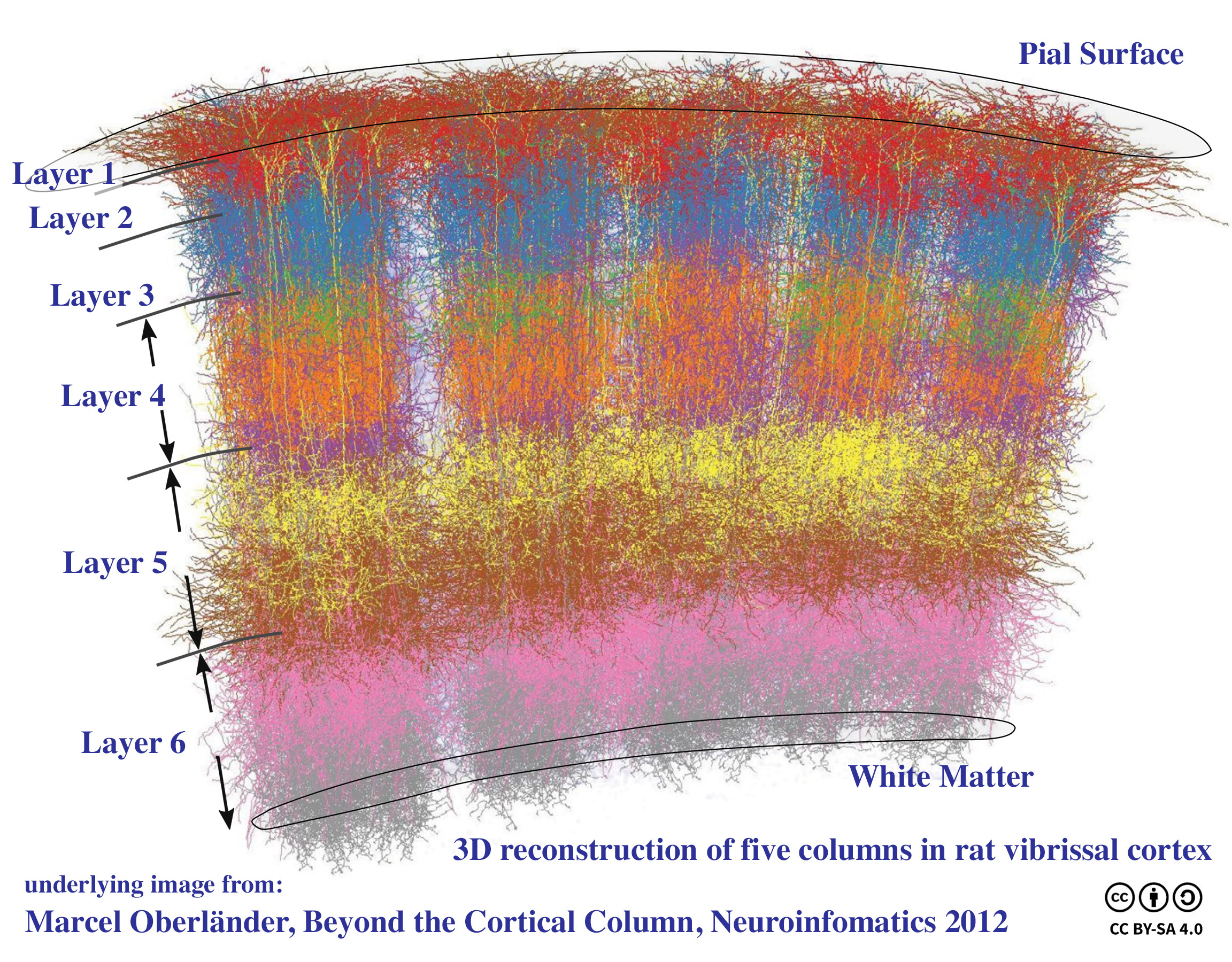
(Source: Wikimedia Commons)
{kind=link}
The downside of associative memory is we can't always find what we were looking for five minutes ago or where we left our car keys. We may have to hunt through our memory but it may be lost to "cold storage" sitting in a cluster of synapses that haven't been strengthened or used in awhile and so weaker and harder to get to at a moment's notice. That's where computer memory comes in.
Computer memory is register based. It is stored in precise locations and associated with a unique number. If you have that number you can retrieve that information perfectly every time. That means computers are masterful at retrieving exact facts or data in a way people just can't.
The downside of register based memory is that if that number is lost, the memory is lost, so it is harder to protect against data loss, even with replication.
But put both register and associative memory together and you potentially have a super memory system with the best of both worlds that mitigates the downsides of a singular system.
And that brings us to the big one we need to solve for AGI, which is closely related to memory.
Continual learning.
Every Day Something New to Know
Right now, machine intelligences are frozen in time.
They get trained and they don't keep learning. When you're chatting with GPT, it's not learning from the interactions and updating its knowledge as it goes. It's a time capsule that ends on its training date.
That's radically different from how you experience the world.
You're learning all the time, constantly updating your world model and self model. You see something that comes into conflict with your understanding and you either find a way to ignore it or you find a way to integrate that new understanding.
To really become powerful, intelligent machines will need to learn online and integrate new experiences.
One of the most promising approaches I've seen is dramatically scaling up Mixture of Experts models. GPT-4 is an 8 way MoE model. MoEs have memory advantages on inference because a number of smaller models are loaded as needed to answer all or part of a question. A router decides which expert to route it to and it's more efficient.
A number of researchers have looked at MoE as a potential way to enable continual learning because you can add more experts and freeze the old ones, similar to how you can add Adaptors, or small additional weights to a model as an add on file. But Adaptors aren't parallelizable in the way MoE models are parallelizable though there has been some work on doing it with approaches like LoraHub, which "fluidly combines" multiple Loras for a given task.
Great, so why don't we just make a massive MoE model and go from there? People tried but it didn't work very well. The main reason was that the router was statically built. That's the part of the model that intelligently calls up one of the experts based on the task or query.
That's where Richard Sutton's Bitter Lesson strikes again. Come up with a static expert system hand crafted by people and it works pretty good but never as good as a neural learned model.
Enter the Mixture of a Million Experts paper by a lone writer, continual learning and transfer learning researcher Xu Owen He, at Google Deepmind. He built PEER, a learnable router that is decoupled from memory usage. It's able to scale to millions of experts and some of the routing neurons are only a single MLP (multilayered perceptrons, the digital building block of neural nets inspired by studying human neurons, though radically simplified from their biological counterparts).
From the paper itself:
"Beyond efficient scaling, another reason to have a vast number of experts is lifelong learning, where MoE has emerged as a promising approach (Aljundi et al., 2017; Chen et al., 2023; Yu et al., 2024; Li et al., 2024). For instance, Chen et al. (2023) showed that, by simply adding new experts and regularizing them properly, MoE models can adapt to continuous data streams. Freezing old experts and updating only new ones prevents catastrophic forgetting and maintains plasticity by design. In lifelong learning settings, the data stream can be indefinitely long or never-ending (Mitchell et al., 2018), necessitating an expanding pool of experts."
Essentially massive MoE models like this hold the potential to lower inference memory consumption and beat catastrophic forgetting by freezing or partially freezing weights and just adding in new experts to learn new information. The neural router is much more effective because it's general purpose and learned. It's like having parallelizable Adaptors/LoRas built right into the model. It also mirrors the plasticity of the brain in that the router can reconfigure itself as new knowledge is learned, much like your brain prunes or strengthens synapses.
The brain analogies go even further in that we have millions of cortical columns in the human brain, as we talked about earlier. In short, our brains are massive parallel processing biocomputers. The bigger we can make an MOE and the better its learned router, the more brain like a model can get.
As a side note, cortical columns are not super cleanly defined so the number that we have in our head depends on who is counting and how they classify them but rough estimates are that we have "50 to 100 cortical minicolumns per cortical column, [so] a human would have 2–4 million (2×106–4×106) cortical columns. There may be more if the columns can overlap, as suggested by Tsunoda et al.[17] Jeff Hawkins claims that there are only 150,000 columns in the human neocortex, based on research made by his company Numenta."
Once you have an ever-learning model like this in place, whether it proves to be this architecture or one of the other ones I'll highlight later from robotics researchers, we can move to a practical life long learning system that mirrors how people process massive amounts of information with a little trick we call:
Sleep.
We learn when we sleep.
There's a school of though that dreams are just our mind replaying our daily experience and integrating that into our understanding of the world, in essence updating our weights, growing new synapses and connections and pruning old ones that no longer predict the world right.
I can picture a model that's storing all its learnings throughout the day or the week in a special purpose database, likely a dual SQL/Vector database and perhaps something more advanced with an in-memory cache, and/or a fresh set of MoE experts added to a model, or maybe a smaller "active" learning neural net or a combo of the above techniques.
Then "at night" or on a schedule, the model is cloned and the clone "goes to sleep" while the main model stays online doing inference. The sleep mode version of the model gets merged with the smaller active model or the new MoE experts. When it's done, the cloned "sleeping" model merges back into the main copy of the model with weight differentiation or some similar technique and it's unit tested against a range of behavioral responses in a blue/green inference test and then when it passes, yesterday's model sunsets or gets archived and backed up and the new model takes over inference.
All of this builds on years of cutting edge research that's often invisible to people outside the AI research community. Much of the older continual learning work is detailed in an excellent article by Tom Chivers in Spectrum IEEE: The Replay technique takes inspiration from how we dream, as outlined above. “iCaRL: Incremental Classifier and Representation Learning” and REMIND networks use variations on that technique to overcome catastrophic forgetting and Chivers notes that Ted Senator, a program director at DARPA, the Defense Advanced Research Agency, is using replay techniques in their SAIL-ON project, which is short for “Science of Artificial Intelligence and Learning for Open-World Novelty” a project designed to teach machines how to adapt to changing rules and changing environments.
Earlier robotics work also mirrored similar ideas to the Millions of Experts approach. Bi-Level Continual Learning and Progress and Compress are two nearly identical techniques, developed in parallel by different research teams, that are essentially a combination of three techniques, progressive neural networks, elastic weight consolidation and knowledge distillation.
Both techniques are designed to overcome the catastrophic forgetting of models and deliver continual learning. They mash up a number of techniques to do the job. The first is “elastic weight consolidation.” It’s basically a way of partially freezing connections in the model. The technique figures out which of those connections are most important. It turns out to be a surprisingly small number most of the time, maybe 5% or 10% and then keeps them mostly frozen in place so they can’t change.
Now you can retrain the network and it can learn new skills.
If you’re paying close attention, you probably noticed a big potential problem with this technique. Eventually most of the neurons will get frozen over time and the network won’t be able to learn anything new.
It’s analogous to the way we learn. As babies our brains are very plastic and we can learn seemingly anything very fast. But over time we have experiences and our mind gets “set” and our connections get reinforced and we have trouble loosening those connections and adjusting how we think or what we can learn. Our connections are strongly reinforced and harder to reconfigure. We start out with a massively connected brain but the brain then rapidly sheds connections and synapses as it grows because its energetically inefficient to maintain them all.
It’s likely one of the reasons why kids can learn languages with lightning speed but it gets much harder as an adult if you don’t have an aptitude for it.
But Bi-Level Continual learning and Progress and Compress deal with the frozen weights issue by having two networks instead of one, a rapid learning smaller network and a huge long term memory network that gets the skills of the smaller network over time.
That roughly mirrors the functioning of our brain yet again. Think of it as the hippocampus and neocortex. As Hannah Peterson writes in her article on catastrophic forgetting, “In our brains, the hippocampus is responsible for “rapid learning and acquiring new experiences” and the neocortex is tasked with “capturing common knowledge of all observed tasks.” That dual network approach is called a progressive neural network.
But there’s an additional problem with basic progressive neural nets. They don’t share information bi-directionally. You train the fast network on one task and freeze those weights and transfer them to the bigger network or storage but if you train the network first on recognizing dogs, it can’t help the new network training on cats. The cat training starts from scratch.
Bi-Level Continual Learning and Progress and Compress both fix that problem by using a technique called knowledge distillation, developed by deep learning godfather Geoffrey Hinton and his research students. Basically, it involves averaging all the weights of different neural nets together to create a single neural network. Now you can combine your dog trained model and cat trained model and each model shares knowledge bi-directionally. The new network is sometimes slightly worse or slightly better at recognizing either animal but it can do both.
And there are other simpler techniques to make an ever expanding mind, namely just using Adaptors and hot swapping them in on a per task basis or as needed, which our team at Kentauros AI is experimenting with now on our AgentSea platform and which Apple recently used for their on-device models.
If massively parallel MoE's take off, then it becomes a simple matter of adapting the technique to train new mini-experts and then weave them into a state of the art open source model that will learn over time, not just from one person or team, but from the whole world.
Experts could be curated and reviewed and tested by the community/developers and the best ones get integrated into the perpetually learning hive mind of the mega MoE model with millions and eventually billions or trillions of experts.
Conclusion
The path to AGI is a long and winding road. While many people think we'll just scale our way to superintelligence with the algorithms we have right now, that's unlikely. It doesn't mean we won't get stronger models as we pour in more data and compute but the technique will only take us so far.
OpenAI's GPT 5 won't just be the same architecture with more data thrown at it. We've already seen that approach doesn't get you much farther since we've had many, many top tier models released since then that aren't much better or worse than GPT 4.
We're already plateauing with current data/techniques.
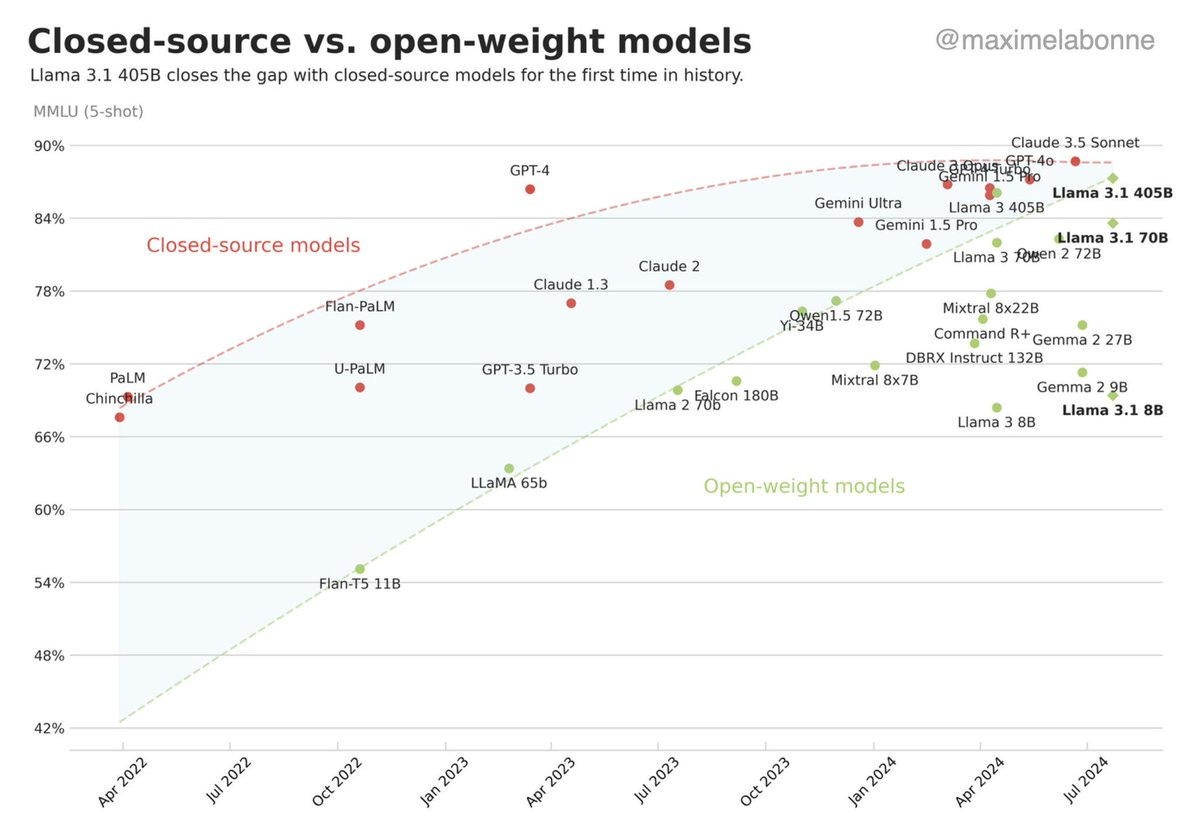
(Courtesy: Maximelabonne)
We need new techniques.
That's why the machine learning community and AI watchers got excited after it leaked that OpenAI was using a newer update to Q* to teach models math and reasoning. The technique comes from an old Google Deepmind technique that taught models to play Atari games with reinforcement learning in 2013.
It's actually not some crazy new AGI technique though. People tend to infuse leaks like this with magical properties. If we look at the Q* paper, it's basically a learned deterministic policy, which means that exploration drops to zero. That's good for games, as it means that the model will never just randomly go right when it's found the optimal path at a certain point is left. It also makes it good at hard reasoning, like math, or formal reasoning like logic.
But what it likely won't do is capture "fuzzy reasoning," the kind of "rule of thumb" reasoning that we do. You might make an unconscious rule in your head that to check that an email was sent you need to look in the "sent" directory, but not always. On some other systems it might be "drafts" or something else and you adapt as needed.
Still, all that means is that it's sometimes helpful to mine techniques from the past and update them with everything we've learned since. Research is all about standing on the shoulders of giants. Like this paper out of Zheijiang Lab, an advanced next-gen research lab in China, where the team figured out how to use LLMs as a teacher for Reinforcement Learning models, with the downstream model slowly breaking away and learning on its own.
The downstream model learns much much faster and it also lets the researchers overcome some of the weaknesses of RL, such as how hard it is to find an effective reward, because the LLM can adjust that reward on the fly at the beginning. Without LLMs this wouldn't have been possible, so it's essential to take old techniques and do what we do best, abstract and combine them into something bold and new.

(The blue line is the LLM teacher model learning much faster versus other RL techniques)
I'm a big fan of looking back from my treasure trove of old AI papers and books from the 70s, 80s, 90s and early 2000s. Sometimes you find a brilliant idea but the necessary pieces to make it work were missing, like another complementary algorithm or the right data or hardware. Many ideas are just ahead of their time. They don't have the right pieces in place to make them work.
Much of the history of AI tells this tale. For a long time, deep learning pioneers kept the torch alight despite very little funding. They had a good sense that their ideas would work but unlike theoretical physics AI is an applied science. If your network doesn't solve a new problem that can't be solved with other methods and it can't generalize beyond a toy dataset then it's useless.
It took the massive treasure trove of data on the web and the rise of GPUs to make deep learning take off. But for a long time neural nets were almost considered dead end research.
There are lots of old ideas like fuzzy logic, evolutionary algorithms and even old languages like Prolog that have a lot to offer the modern day machine learning practitioner. You shouldn't assume that just because an idea didn't work in the past that it can't work now.
That's what my friend David Ha at Sakana AI did with evolutionary algorithms. He and his team applied them to model-merging to get incredible new skills by intelligently merging models together.
In their proof of concept, they automatically evolved an LLM capable of strong math reasoning, and a Japanese LLM. The math model didn't have good Japanese skills and vice versa. By combining models that were good at one or the other they got a brand new model that was good at both.
No matter what though, if I have one lesson for anyone on the cutting edge of next gen AI, it's this:
Further.
There is always further to go.
We have a lot of pieces in place but not all of them. Some problems will be solved with scale. Some need new algorithms. Some need new hardware and software. Others need new data or a new approach altogether.
We already have super machines and tomorrow's super machines will make today's models look like Atari games next to PS5 games running Unreal Engine 5.
Technological evolution happens slowly, step by step, building on the backs of millions of tiny breakthroughs through the collective intelligence of mankind. It goes slowly and then all the pieces are suddenly in place and we get a burst of brilliant new activity that takes us to the next level "overnight."
But there is always further to go.
And we get there slowly but surely, with each new step.