

Meet Robbie - Our Gen 2 Agent
Robbie Navigates GUIs and Does Tasks for You on the Open Web and He's Fully Open Source and Available Right Now


Meet Robbie, our Gen 2 agent.
He's available right now on Github and he's completely open source.
You can download him immedietly and modify him and send him out into the wide world of the web to do tasks for you. Robbie navigates GUIs to solve tasks for you and he runs on top of various tools from our AgentSea stack.
Check out our Deep Dive video below and you'll find even deeper dive right here in this article.
You can see at various points how Robbie works his way out of problems and works through the GUI to do what he needs to do for you.
Let's walk through a bunch of techniques we use to help him on his way, which we've pioneered over the last few months, and after that we'll walk through some failures and then show you what we're doing about them.
We'll show you where he rocks and where he sucks too.
How Robbie Came to Be
But first a little background on why we're doing this:
My friend, David Ha, of Sakana AI, told me to avoid GUI navigation like the plague because it's a notoriously tricky problem that many have failed at over the years.
He was right. But we didn't listen.
And that's because the web is an absolutely fantastic arena to teach agents how to solve really complex, open-ended tasks. It's completely untamed frontier with many stochastic elements that hasn't yielded well to Reinforcement Learning. It's filled with sparse and very hard to define rewards.
Just like in robotics, where a robot may make an imprecise movement and knock something over or not put its fingers exactly where it expected, the next predicted state versus the real world state might be wildly off. A GUI nav agent may click the wrong spot, or the page may crash, or its reasoning may be wrong and it clicked "drafts" instead of "sent" to verify an email was sent, leading it down a wrong path.
The edge cases are endless.
That's why the wild frontier of the world wide web helps us work out more advanced reasoning and planning in agents and to see the limits of today's models (and there are many).
Applied AI teams like mine don't train the models from scratch (though we do fine tune/augment them.) Above all, applied AI teams are practical. We work with what we’ve got, warts and all, and we find solutions to work around weakness and play up the strengths of these marvelous little machines known as Multimodal Large Language Models (MLLMs). They are indeed marvelous but they're painfully stupid too.
Along the way, we're advancing the state of the art and we've got tons of room to grow and practical ways to get there.
Robbie-g2, aka Gen 2, is a leap from our first gen agents, SurfPizza and SurfSlicer. He's very capable at navigating complex, never before seen GUIs via a remote virtual desktop which the AgentSea stack serves up as a device to him via DeviceBay. He connects to it via ToolFuse and AgentDesk, which lets him know what he can do with it, like move the mouse, send key commands, etc.
Robbie g3 will be an even bigger leap as we imbue him with better mental models, a larger prediction pipeline, async/parallel planning and long and short term memory. More on that at the end.
But let's start with what works and why it works and why it's new.
The Mind of Robbie
While many teams are using the "team of agents" approach, like the excellent CrewAI team, and getting some cool results, we prefer modeling the parts of the brain in our agents, similar to the "thousand brains" approach of making decisions through consensus of different parts of the "mind" of the agent that excel at different pieces of the puzzle.
We divide our Gen 2 agent into the following:
Actor
Critic
Neocortex
Body
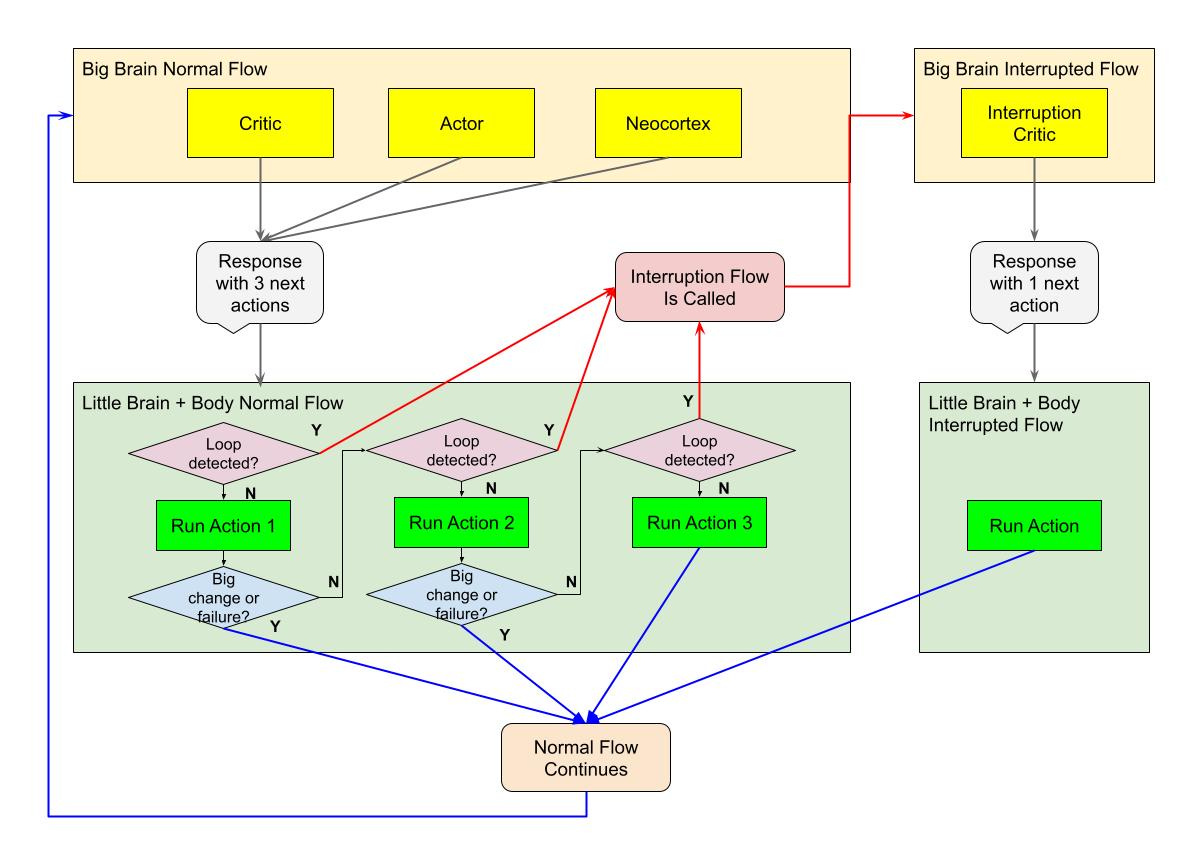
The actor is the primary decision maker of the agent. He makes all the decisions and takes actions in the real world.
The critic studies actions and considers whether they were a success or failure as well as alternative paths and ideas.
The neocortex does a lot of things in the human brain, as it takes up over 70% of the space in our heads, but in our case we use the neocortex to predict the next few actions. The neocortex is the seat of "simulations" into the future, letting us make decisions in real life before we make them and play out how it might go, so we can pick better actions.
In later versions we will make a more complex long term and short term prediction system but in this case, just predicting they you have to first type a search into Google and then hit the search button is pretty strong for us already.
The body takes actions through its tools, in this case the virtual desktop served up by AgentDesk.
It's a hacky approximation of some of the concepts in Yann LeCun's next-gen neural architectures and it also takes inspiration from Richard Sutton's reinforcement learning work and builds into our own next-gen architecture which we'll share later in the post.
Again we're not training novel architectures, but as an applied AI team, we're doing what humans do best, we're abstracting ideas and applying them in new and novel ways.
Now let's jump in and see through Robbie's eyes.
How Robbie Sees the World
Robbie is a pure multimodal bot.
Like a Tesla car, he makes decisions only by what he sees and reads.
(Though not as advanced as a Tesla...yet!)
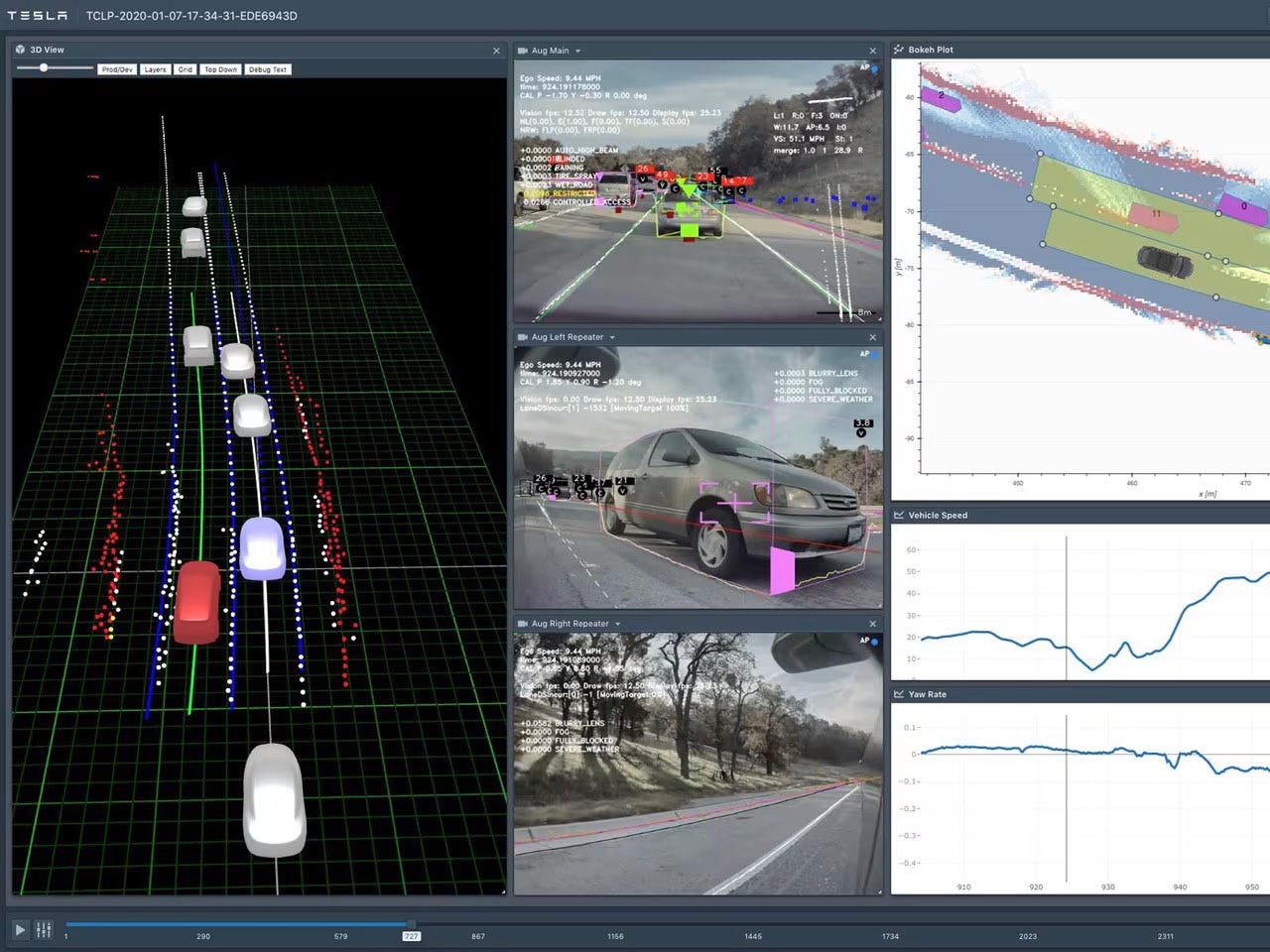
(Image courtesy of Tesla team and their awesome tech deep dive.)
Most of the agents out there today use something like Playwright to script browser interactions. That's a cool approach and you can easily use Playwright as a loadable device/tool in the AgentSea ToolFuse protocol but this doesn't help if you want to click around a desktop or a mobile app. For that we knew we needed a pure multimodal approach.
Just one problem.
We discovered that models like GPT-4/4o and Claude Opus/Sonnet are absolutely terrible at three key things:
Returning coordinates
Moving the mouse
Drawing bounding boxes.

The reasons shouldn't be surprising. They just weren't trained to do any of these things.
But we've pioneered a number of tricks to help the models give us what we need to get through a GUI dynamically.
We divide our techniques into "cheap" and "expensive." We don't mean money wise, although these agents can eat tokens like Pac Man so they can be expensive that way too.
By "cheap" we mean quick, dirty and fast.
By "expensive" we mean round trips to the cloud and using heavier/slower frontier models or big open source models to get what we want.

We try to use as many cheap methods as possible because they are much faster. There are a number of ways to squeeze amazing results out of smaller, cheaper, faster methods and classical computer vision if you get creative, which is the essence of applied AI.
But for approximations of higher intelligence you need the much slower frontier models and there is no getting around it and that means everything slows down considerably because of round trips to the cloud and the slow inference of these models.
Robbie uses three major techniques to navigate the web:
OCR Positioning
This is our absolute favorite cheap method and it’s lightning fast when it works.
A few months ago I wondered if we could use the position of OCRed text as a way to get coordinates for buttons and links. Turns out we can. Many models and libraries like, Tesseract, support getting text position back.
Unfortunately, most of them are not very good at accurately OCRing and giving coordinates. That set us off on a search to find the right model. Some were too big and too slow and most of them just, well, kinda sucked.
And then we hit on EasyOCR.
It is God like at finding text accurately and it is super fast and lightweight.
When we first ran it through our test suite of GUI images and it came back with 100% we thought it was a mistake but subsequent tests proved its very strong (though not 100% in real world settings by any means.)
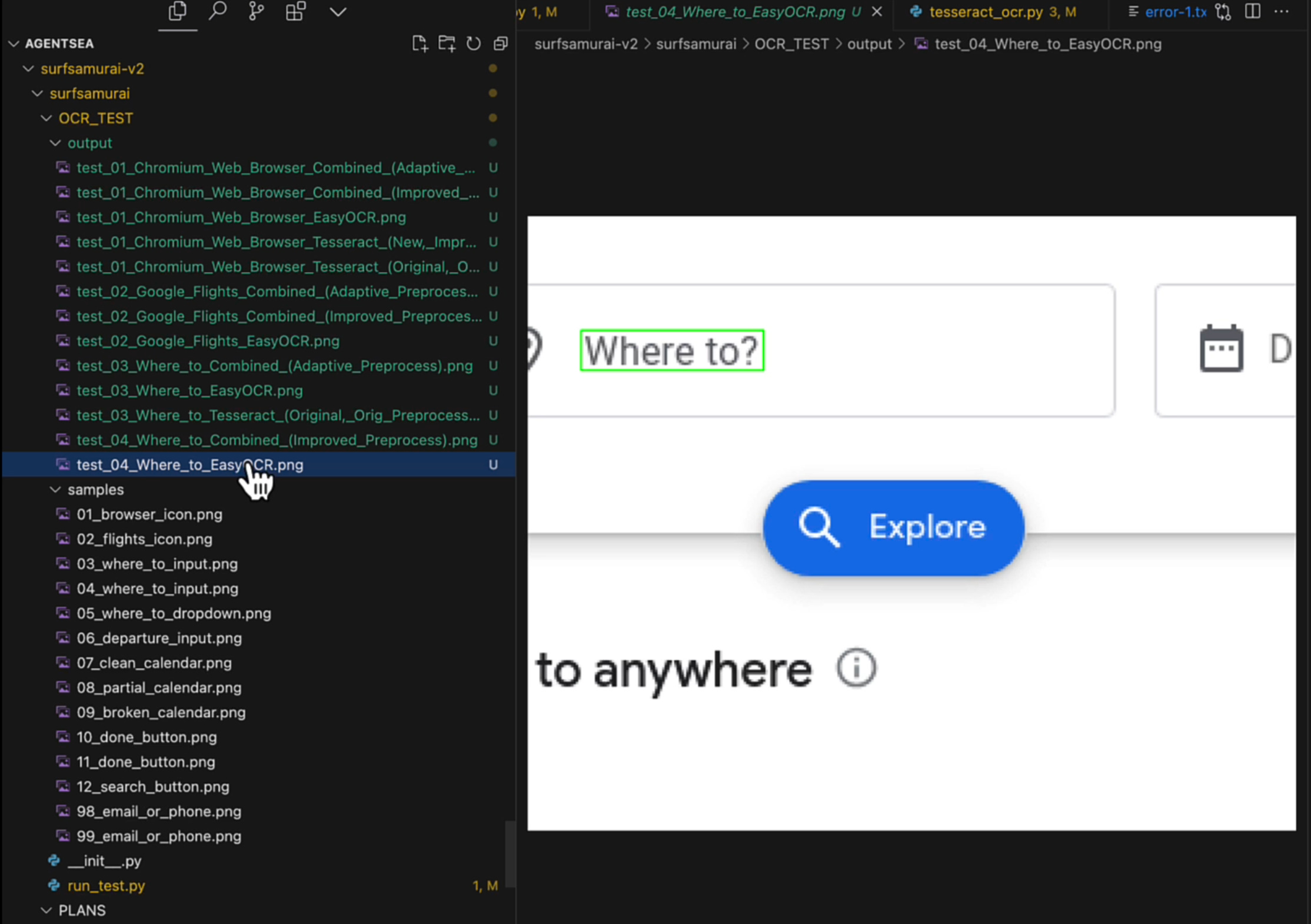
If the element on the page has text it is usually easy to find. The MLLM tells us what is it looking for with its next action description and if we find a match we can easily click it quickly without more round trips to the Big Brain in the cloud.
The Grid at the Center of it All
While models are not very good at knowing precisely where to click they are good at knowing approximately where to click. They can tell you that the search button is in the middle of the page or on the lower left corner.
So we help the model do this with much better precision by layering a bunch of dots with over the image and ask it to pick the number closest to the thing its looking for right now.
Honestly, it’s easier to show than to explain because it makes intuitive sense when you see it:
From there we can progressively zoom, based on the number the model returns, overlaying the screenshot again, to get more granular and zero in on what we want to click. In the below screenshot, you see a second level zoom on Twitter as the model looks to find the "compose tweet" button.

This approach is slow but it works very, very well.
It's biggest downside is it's "expensive" in that it involves as many as three round trips to the cloud to talk to the Big Brain in the sky.
Region of Interest
Region of interest is a hybrid classic computer vision and Big Brain in the cloud approach. It's faster than grid but still slower than OCR.
In essence, it involves using canny in opencv to find all the right bounding boxes and then intelligently splitting the regions so that they show entire sections without cutting off parts of the piece of the puzzle the model is looking for at the moment.
We then layer all these regions onto a grid that we call the "Jeffries Composite" and asking the model to pick the number that has the element it wants. Again, it is easier to just show you:

In older versions of our agents, our desktop slicer often cut right through the element we were looking and so that search bar or button spawned two or three boxes, which confused the model. By intelligently not cutting something that is in the middle of a bounding box, we now get very clear sections of the image to work with 95% of the time.
Combined, these three techniques do very well at finding their way around a GUI, even without any model fine tuning (which we're working on too and you can read about here.)
Fine tuning will give us a much faster and more robust clicking model and we'll fall back to these classical techniques as needed in v3.
Problems
Okay, now that we talked about what works, let's talk about what doesn't work.
And let's be crystal clear, there are still problems.
One thing our team does not do is hype and bullshit and we do not promise you perfection at this stage in the early evolution of intelligent agents. We build in the open and that means showing you what's going well and what's not going so well.
Consider these agents experimental and something you can build on yourself with your own ingenuity and creativity.
We divide problems into two broad categories:
Big brain
Little brain
Big brain is any frontier model that we tap for reasoning and planning and taking actions.
Little brain is all the heuristics and tricks we just went through, like using EasyOCR, OpenCV and our own algorithms to find information on the page and effectively navigate GUIs.

As you just saw, we've solved many of the little brain problems. We can find our way around the maze of a GUI most of the time.
Big brain problems are where our agents (and everyone else's) still struggle at times.
We're building heuristics and guardrails to compensate for this better in v3 but v2 still suffers from the often absurd reasoning and lack of "common sense" in these frontier models. We're pushing the absolute limit of what models like GPT-4/4o and Sonnet-3.5 can do.
What do we mean by common sense?
If you were naked and I told you to run down to the store you'd have the common sense to know you should probably put some cloths on, even though I never explicitly told you that.
Here's another example from Max Bennett's amazing book A Brief History of Intelligence. I started with the line "He threw a baseball 100 feet above my head, I reached up to catch it, jumped..." and let it finish the sentence.

Because of your common sense, you'd know the ball was too high to catch.
Today's frontier models still lack common sense in most novel situations even after being fed a lot of common sense reasoning text that allows them to cheat on common sense benchmarks but don't allow them to generalize that common sense to never before seen tasks.
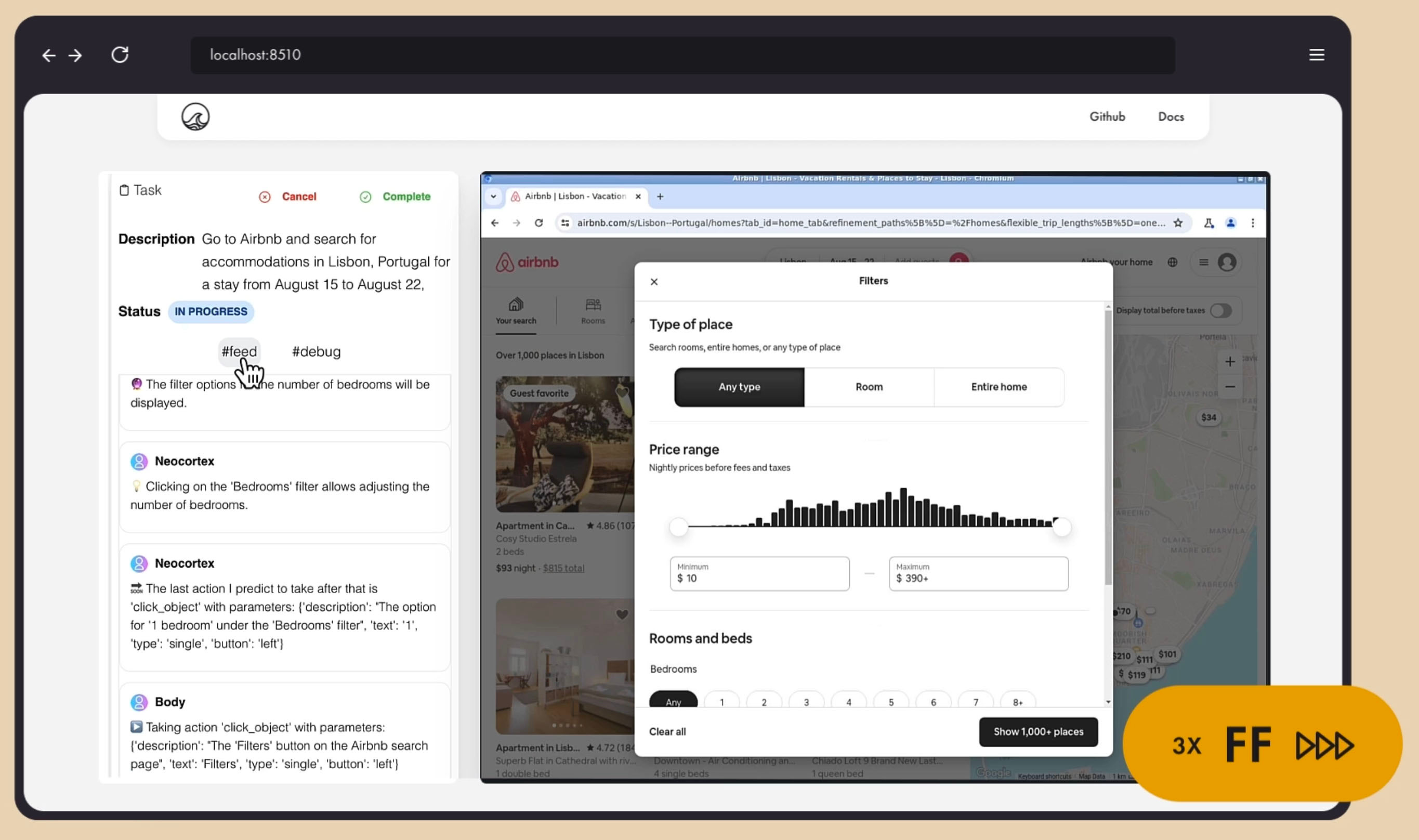
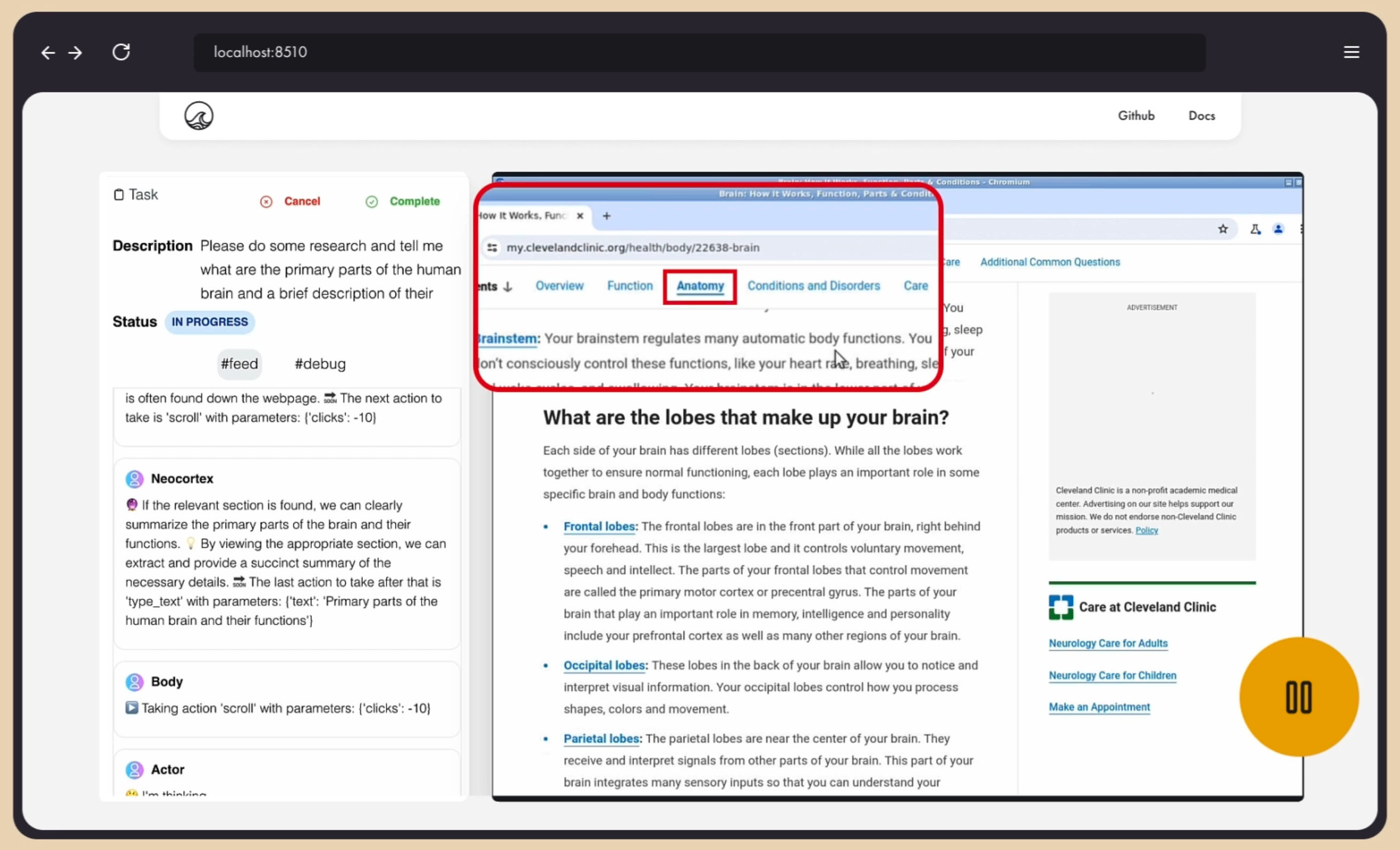
You can see an example of big brain/common sense problem in the debug sequence below. I told it to "go do some research on the brain and tell me the various parts of the brain and give a quick summary of what they do."
It opened Google (good) and the agent's Neocortex correctly predicted it would need to type the search text and click search (great).
See below.
(Please forgive the low quality of the debug image but we don't need high rez images for debugging as they take up space and we just need to review the cascade of images to understand what's happening.)

That's all good but here's where the problems started:
It decided to type text without the search bar in focus so the text went into the void. It did not understand that it had failed to type the text correctly in the previous step and so what did it do?
So what did it do?
It clicked the search button anyway! And, of course, since there was no text there, the button did nothing!
I was in a Spanish territory when it was testing that day so that's why it's clicking on "Buscar con Google" which is "Find on Google" if you don't speak Spanish. That would have been correct if it had already typed the text but it didn't have the common sense to know that it had failed to type correctly earlier.

Even worse, it did this a few times, hoping for a different result. Eventually, the critic stepped in and gave it an alternative path and it decided to just type the search into the URL bar and that worked.

What's Next
We're working towards a much more advanced architecture for agents that we call.
We call our aspirational architecture:
PSDA or Plan, Simulate, Decision, Action.
Now let's be clear. This architecture is crazy next-gen and aspirational.
Some of this architecture is possible now.
Some of it's possible with next-gen frontier models that are cooking as we speak.
Some of it will be possible with newer and more advanced general purpose algorithms from the big labs and the top researchers in the coming years.
And some of it is not possible at all without some real, novel breakthroughs.
That said, we also feel that it is possible to approximate much of it over the next few iterations of our agents with heuristics, hacks, creative thinking, ingenuity, luck, glue and chewing gum. It won't be perfect but it will be a lot better than what we have today.
So that's what we're working on next. In G3 we're working on:
Async/parallel next step predictions
A prediction tree
Long and short term memory, split between vector and traditional SQL
Better Big Brain guardrails
A fine tuned click model
All that is subject to change as we work through the fun and fantastic world of bleeding edge agents and let our creativity run wild.
At every step we learn something new and it changes our trajectory slightly or wildly.
But with each new day we get closer to a general purpose agent that can solve complex tasks in the real world.
We’re also going to make this code much cleaner in later generations and break out a lot of our tricks into classes that are more easily reusable by other teams.
But it’s still workable today.
So get out there and have fun with Robbie G2.
Here's the repo again.
See if you can improve on what we did. We’d love to have fresh ideas and more brains working on the problem because that’s the true power of open source.
And we’ll see you in Gen 3.