Embracing the Bitter Lesson
Why So Many People Get the Bitter Lesson of AI Wrong and What You Can Do About It. Aka, How I Learned to Stop Worrying and Love the Sweet, Sweet Sound of GPUs Go Brrrrrrrr.


In 2019, AI researcher Richard Sutton, one of the godfathers of reinforcement learning, penned a fantastic and striking essay called "The Bitter Lesson."
Its first line delivers its killer insight:
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin."
It's a lesson you'd think people would embrace with open arms. But as Sutton says later, they don't:
"This is a big lesson. As a field, we still have not thoroughly learned it, as we are continuing to make the same kind of mistakes."
I've read half a dozen responses (1, 2, 3) to the article and not only do many people not get it, they misunderstand it too. Critics tend to hear two things in it:
Supercomputers/ML and search are king, aka GPUs go brrrr
Everything else, including humans, are irrelevant
The first line is right. The second is a bad misreading of what Sutton is saying.
To start with, it makes perfect sense that more compute magically scales up the power of your AI. That parallels real life. Bigger and more complex brains equal more complex capabilities in animals.
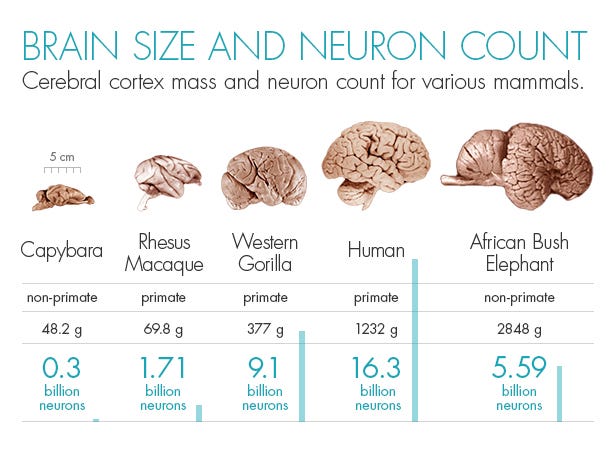
(Source: Quanta Magazine - not a measure of absolute neurons but neurons in the cerebral cortex which are thought to be the focus of cognition capabilities in animals)
An ant can't create art or build new technology like a human because it has a far less complex brain. Our integrated circuits today, while possessed of incredible capabilities, are still far less powerful than the human brain. A human brain has over 100 trillion connections and runs on potato chips and coffee at 20 watts.
We can think of the human brain as a "linearly scaled up primate brain."
We haven't even come close to human level complexity with our current deep learning super models on our fastest tensor chips. To get there we need more computing power, a lot of it. As Nvidia CEO Jensen said recently, he expects one million times the compute in 10 years. That will get us a lot closer.
It’s not a perfect analogy, as the paradox of the elephant shows us (it’s got a bigger brain and more neurons [about 3X] and it’s not smarter) but in general when it comes to brains, bigger and more connected does equal better, even if it is more neurons and connections in a single part of the brain (the cerebral cortex) on a pound for pound basis.
So yes, one of the bitter lessons is that supercomputers are king. Just add more GPUs. GPUs go Brrrrr. Scale up as big as you can.

But it's not the whole story.
Way too many people read Sutton and think that means humans are all but irrelevant.
The misunderstanding seems to come from this line:
"AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning."
People react at a gut level to this line. They react with secret revulsion. It's as if he's saying humans are useless and don't matter and all you need to do it throw more data and compute at it.
It feels too much like blind evolution.
Ironically, many AI researchers believe in a kind of intelligent design and the unique nature of the human mind whether they know it or not. Accepting that intelligence might just come from jamming together a lot of neurons and letting the system brute force figure it out on its own feels downright barbaric.
That's because the other major approach to AI is the one every researcher secretly loves. It's where you add lots and lots of human hand-coded ideas and domain knowledge to a system, making an expert system. It usually works well in the beginning but quickly becomes a bottleneck and limiter. Almost every time, as the researchers remove that human framework the model gets better, smarter and faster.
Michael Nielsen makes the mistake in "Reflections on a Bitter Lesson". He writes that Deep Blue didn't just use massive compute and brute force search methods. It had "roughly 8,000 features which Deep Blue used to evaluate board positions. Many of those features, like that of rooks on a file with a levering pawn, were based on deep domain knowledge of chess."
He's right, there was a ton of domain knowledge baked into Deep Blue, in addition to its super powered, custom built supercomputer chess chips and brute force search powers. But he's missing the point for two reasons:
The first is that none of that domain knowledge worked without that compute muscle behind it. Earlier chess engines were weak, no matter how much domain knowledge they had baked into them.
The second reason is right in the line we quoted earlier: "AI researchers have often tried to build knowledge into their agents, this always helps in the short term, and is personally satisfying to the researcher, but in the long run it plateaus and even inhibits further progress."
Deep Blue's approach worked in the short term but not the long term, as we'll see just in a moment.
And read what Sutton wrote again in the opening paragraph:
"general methods that leverage computation are ultimately the most effective, and by a large margin."
"General methods" is key to understanding here.
He's saying that if you're a researcher, spend your time on new machine learning algorithms that generalize to a huge number of tasks and that scale with more processing power. Don't waste time trying to create heuristics that bake in a tiny fraction of human knowledge, like rooks on file with a levering pawn. Don't waste time on little ideas and writing a rule about why it's better to control the center of the board in chess engines.
"One thing that should be learned from the bitter lesson is the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great. The two methods that seem to scale arbitrarily in this way are search and learning."
Humans still have to write the algorithms. They're not irrelevant. They're just writing the wrong algorithms much of the time, instead of focusing on the ones that will work best, general purpose learning algorithms and search algos that get better when you hurl more compute at them.
Neural networks and by extension deep learning, especially Transformers, are generalized learners. Backpropagation is a circuit search algorithm. Evolutionary algorithms are basically search that culls the search down to a smaller subset of choices to get to better optimization. Q-learning is a way to discount future rewards in favor of short term rewards and works well as a generalized way to define how to assess the way forward for an agent. Monte Carlo (MCTS) is search that applies to many kinds of games and other problems. They're useful when there are so many choices it's impossible to brute force through them all, which is true of so much in life. The list goes on and on.
Sutton's own work on Reinforcement Learning is a prime example of it too. RL is a general purpose learning algorithm. It's simple. Punishment and reward. Give a system a goal and tell it whether it's getting closer or farther from its goal. Simple and effective. It can generalize to many different tasks. A modified version of it, RLHF, Reinforcement Learning with Human Feedback, is part of the magic behind GPT-4, where they fed it a small subset of human labeled conversations to steer it in a particular direction and get it better aligned to values.
All of these methods can be applied to a wide range of learning tasks. They can't do everything but they apply to a huge range of challenges rather than to one tiny problem.
What happened with chess engines over time is a perfect example of small, baked-in knowledge approaches plateauing and generalized methods smashing those approaches later on down the line.
After Deep Blue, multiple chess engines flourished, culminating in Stockfish, the undisputed software chess champion. It went on to dominate computer and hybrid chess championships for years. The open source software used several generalized search algorithms such as alpha-beta search. But it also includes domain specific knowledge in how it evaluates positions. It "encourages control of the center of the board" and "penalizes doubled, backward and blocked pawns."
For many years it was largely unbeatable.
Then came AlphaGo Zero.
AlphaGo Zero was the successor to AlphaGo, the platform that beat Lee Sedol. AlphaGo included a great deal of human knowledge baked into it too. It learned from human games to build its policy network. It had a ton of glue code to write around problems. Of course, it also heavily leveraged search and compute with Monte Carlo and deep learning training on lots of data.
But AlphaGo Zero used no domain knowledge, just pure generalizable learning.
Zero knew nothing about chess except the basic rules. It had no domain knowledge baked in at all. It wasn't told to control the center of the board or penalize pawns like Stockfish. It leaned by playing itself again and again via RL. It got punished for losing and rewarded for winning.
It did the same for Go. No domain knowledge, just the basic rules. Play. Evolve. Reward. Punishment.
AlphaGo beat Lee Sedol 4-1. AlphaGo Zero beat AlphaGo 100-0.
And Stockfish?
In a 1000-game match, AlphaZero won 155 times with only 6 losses and 839 draws.

(Source: Lichess)
In other words, over time, generalizable methods win out over specialized knowledge. Let the machine find the best answer instead of trying to work in how we think that we think.
A similar thing happened with spam filters in the late 1990s. For many years the spam problem was heating up and most people's inboxes were overrun with unsolicited messages that made reading email painful. Programmers saw that and naturally gravitated to rules and human domain knowledge. It's a natural inclination. A programmer reads an article that begins "Dear Friend" and thinks, "How dare they, I can write a rule to stop this crap now!"
Over time we got a towering inferno of human written rules that were about 70% accurate, which meant a lot of spam still got through as spammers continued to adapt to those systems and sneak around them, often by stacking in lots of normal text at the bottom of an email but keeping the text invisible so that it overwhelmed the rules.
Then came Bayesian filters, a generalized approach to learning. Basically, you take a few hundred year old statistical method, created by a Presbyterian minister, and turn it into a spam classifier. You feed the classifier a corpus of ham and spam, and you let the machine figure it out. Suddenly you had filters that were 98% accurate, smashing the old filtering methods.
Generalization beats domain knowledge yet again.
Of course, there are some exceptions to these rules. Sometimes, the research simply hasn't progressed far enough into a generalized method for a particular set of tasks and so heuristics and rules might be the only way forward at the time.
Those rule based spam filters were better than nothing and kept my inbox from being an absolute dumpster fire, even if I still had to wade through a lot of junk mail. Without them my inbox had become a nightmare of noise to signal, with a few hundred spams for every one real message from a friend or coworker at the time.
I thought of another example when I saw the release of Microsoft Security Copilot. It pulls in data from a ton of sources and its ML model detects attacks and offers recommendations. About twenty years ago I wondered if we could use AI baked right into routers to detect malicious attacks and cut them off in real time. I couldn't find a way to make it work. In retrospect, it's obvious why. The datasets where there, as there was a ton of network traffic in the world, and that made it one of the few large datasets at the time, but the compute wasn't there, not to mention ML wasn't really up to speed as it was pre-Alexnet and that meant the systems weren't fast enough to process novel anomalies in real time. But for many years, security researchers did just fine with heuristics to stop many network attacks. They used what they had when a better method just didn't exist and that's perfectly fine.
As I thought about this, I had little doubt that someone like Cloudflare could now train a model on oodles of network traffic and attacks and then deploy that model to the edge to stop attacks in real time as long as the confidence was high and if it wasn't it could pass that traffic on to people for a deeper look. I wrote that last sentence and looked it up and that's exactly what they've done a few years ago. Twenty years ago my idea was like Babbage's analog computer, missing several components to make it reality, but now it's possible.
From the blog:
"On top of that, we validated the model against the Cloudflare’s highly mature signature-based WAF and confirmed that machine learning WAF performs comparable to signature WAF, with the ML WAF demonstrating its strength particularly in cases of correctly handling highly obfuscated or irregularly fuzzed content (as well as avoiding some rules-based engine false positives)."
In other words, a first pass out of the gate at training a generalized model was on par with a very mature set of rules and outperformed it on highly challenging cases. It probably would have done better if they were allowed to use all the data that passed through their gates in any way they saw fit. But Cloudflare suffered a bit as they can't use a lot of it by contract and by regulation and for privacy preserving reasons. The data they can use is sensitive so they have to go to great lengths to anonymize it and strip it down so it's likely their models suffered from that restriction because it forced them to use some data augmentation to make up for it. But there's little doubt in my mind that a second or third gen model will eventually smash those rules based systems, especially if they had access to the unfettered data.
I'll also concede that it's possible that we have to start with domain knowledge and heuristic based approaches in order to learn how to turn that into a generalized system later. Maybe we have to hand code our ideas until we can start to break them apart and understand them? Maybe it's a part of the progression of knowledge? It’s totally possible that that’s the one real chink in the armor of Sutton's observations.
But so what? The overall message remains and it’s a strong and simple one.
If you can focus on a generalized method of learning and search right away, then do it. If you can't find a generalizable method right now, it's fine to start with domain knowledge, but be ready to adopt generalized methods as quickly as possible or you'll find yourself outmoded.
So if you're a researcher out there and you want to work on algorithms for training AIs like we train little kids, aka with little data and just a little bit of instruction and mimicry, then go for it because that kind of generalized learning breakthrough can and will change the world. But if you feel like writing an algorithm or a rule based heuristic for evaluating pawn positions in chess then don't bother unless you've checked to see if there is a generalized method you can use first and only do it if you've got absolutely no choice because the state of the art hasn't caught up to your ideas yet.
GPT-4 is a testament to GPUs go brrr.
But it's also a testament to human ingenuity.
Google put out Bard and it doesn't perform nearly as well as their rival's mega-model. Google has more compute than God so it stands to reason they could train the biggest, baddest model but it's not happening. So what else is missing?
Again, human ingenuity. Abstract thinking. Adaptability. New ideas.

There's a lot of ingenuity in GPT-4. It's not just a big, scaled up model. It’s got human preferences woven into it by generalized learning approach like RLHF, aka Reinforcement Learning with Human Feedback. It's also a triumph of red teaming, with security teams role playing GPT-4 and helping refine it with that human feedback as well. A lot of AI doomsday cultists think GPT is just a dumb stochastic parrot with no actual grounding in reality, and while that's partially true, a lot of what they did was give the model an anchor in the real world. Code comments link up to real code and that's a kind of grounding, as Yoav Goldberg points out so brilliantly in this article. It’s matching natural language to the thoughts that produced the code and the code that goes with it. Description and action all rolled into one. There’s also instruct tuning of the model. Instructing it with human chats and preferred outcome chats unlocks a lot of hidden and latent capabilities in the model and steers it towards something much more useful and more grounded in what we want.
So people can rest assured that human ingenuity, abstract thinking, values and logic are still incredibly valuable in machine learning. And so are researchers. Humans are still very much needed in this process but just know that the best way to incorporate them is to give them a simple method of imparting their preferences on a model, rather than trying to bake in our values with a small rule or heuristic.
Humans had to do what they do well, come up with ingenious ways to generalize statistical based learning and ways to incorporate their feedback into the model. Without that it wouldn't matter how much compute anyone had, as other lesser performing LLMs have shown.
The algorithms matter and people do too.
But the kinds of algorithms that generalize are what you want to spend your time on.
Because in the long run, that's the one that's going to beat out your rule based system, so you might as well work on it sooner rather than later.
And after that, all you need is the sweet, sweet sound of GPUs purring in a datacenter far far away.
Brilliant and concise, thank you.