Nine Big Predictions for AI in 2024
AI will be a big year for open weights models, agents, hacks, new model architectures, legislation, legal cases and so much more. Welcome to battleground AI and the war for the future of technology.


I've written before that prediction is a tricky business.
One thing I've learned in my futurist work over the years is that it's often easy to get the developments right but predicting exactly when they happen is usually the hardest part. I've often gotten things perfectly correct only to be off on the dates by a few years or a decade.
I wrote an article 20 years ago and then updated it seven years ago about how video game engines would hit perfect photo-realism and converge massively with movies and film. It felt very close at the time I wrote it, but it took a long time until we got to Unreal Engine 5 powering TV shows like the Mandalorian while also powering games on your PlayStation 5.
So predicting that all this stuff will happen in 2024 is a big gamble. Take the exact year with a grain of salt but the seeds of everything I write here are happening now and if they take a few more years (or a decade) then so be it.
With that said, let's leap into it.
I'll start with a surprise and a potentially controversial one.
1. A major proprietary model (such as GPT 4 or Claude) will get hacked and its weights leaked and/or released.
A recent article in Venture Beat, detailed the obsession by Anthropic's security team with protecting their model weights from getting into the wrong hands. I love and applaud their tight focus on security because way too many companies see security as an after thought.
Unfortunately it just won't matter.
The problem with security is you have to play perfect defense 100% of the time and the attackers only have to succeed once.
As these models grow in importance, they'll increasingly become the target of APTs (Advanced Persistent Threats) aka government sponsored hacking teams whose job it is to break into companies and steal secrets. They have all the time and money in the world (not to mention legal immunity) and they keeping coming at you day, after day, after day, aka advanced and persistent.
Governments around the world will want these models for themselves, especially for surveillance and military purposes and they won't rest until they've got them.
If it isn't an APT, it will just be a regular hacking group looking to hold one of these companies hostage or release the model for the lulz, aka because it's fun to them. Check out the recent hack of Insomniac Games, where a Ransomware group released videos and playable versions of an upcoming game, Wolverine, along with "sensitive employee data, financial information, corporate planning documents," and more, according to Ethan Gach at Kotaku.
The weights are just too rich a target and basically too easy to exfiltrate. Model weights are small files, a terabyte at most and usually much, much smaller. Anyone who finds a way into the citadel through a classic spear phishing or social engineering attack will walk out with the weights faster than they can say "we got 'em."
Take a look at one of my favorite visualizations on the web, the World's Biggest Data Breaches and Hacks. It shows major hacks around the world stretching back twenty years.

(Source: Information is Beautiful)
Here's a quick list of more recent hacks:
The Indian government's biometic and identity database called Aadhaar lost the critical data of over a billion of their citizens in 2017.
Facebook got taken for phone numbers and PII (personally identifying information) of 533 million people.
The Shanghai police leaked the records of over a billion Chinese citizens in 2022.
Marriott International got jacked for the credit card, PII and history of stays at their hotels, to the tune of 383 million people.
I was covering Sony as a customer back in 2011 while working at Red Hat when they got smashed for 76 million Playstation accounts and were knocked offline for 23 days as hackers gleefully deleted backups and wreaked total havoc on their internal systems.
Equifax lost the personal credit card data for half the United States.
And a company with a few hundred people is going to somehow fend off an army of hackers?
No chance.
Not even a well funded small company with a few hundred people.
Honestly, these companies are probably already hacked. I'd be shocked if one of the major Chinese APTs didn't already have GPT 4 and the background to make the model. APTs don't advertise their wins. They hack for the economic and national benefits of stealing industrial trade secrets.
APTs are just Mercantilism for the digital age.
So this one is a biggest lock of my nine predictions.
And if this doesn't happen in 2024, it's a 100% lock over the next five years.
2. An open weights model will surpass or equal GPT-4 on most major benchmarks
I wasn't fully bought in on this one but Mixtral 8x7B convinced me.
Mixtral came out of nowhere and rocketed up the Chatbot Arena board past proprietary models like Claude 2.1, Gemini pro and GPT 3.5, so we're close. So close.

(Source: Hugging Face leaderboard)
My open source roots go back a long way, over twenty years. I built Linux web farms for a pre-Amazon API based multi-vendor e-commerce site and other systems like it during my work as a systems consultant over a decade. Then I went to work at Red Hat thirteen years ago when there were only 1400 people. Back then most sys admins told me to get out because Linux and open source would never surpass the stability and scalability and support of proprietary Unixes.
All of those sys admins are gone, wrong or retired.
That's because open source is sneaky. It always starts off behind proprietary software. It's ugly, meritocratic and powered by the swarm intelligence of lots of people working together in a strange, disjointed way. Sometimes they even work at cross purposes and somehow the software converges at the end to something that works.
Eventually, over time, like the sea wearing down a rock, open source overwhelms proprietary software.
Open source software powers the vast majority of the cloud, the servers on the web, your smart phone, the router in your house, nearly 100% of the super computers in the world, along with nuclear subs, machine learning models and ham radios. There is no reason to think it won't dominate AI as well over the long haul.
Of course, open source software is not good at everything. Proprietary software often feels more seamless and comprehensive. Proprietary software is clean and integrated whereas open source is often messy and all over the place. You have to do work to put it together, like piecing together Legos to build something. But that very messiness allows you to use it in ways that the creators never imagined and proprietary software almost never gives you that freedom.
And what open source does better than anyone is infrastructure software and engines. They do the behind the scenes work, the plumbing better than anything.
And that is what AI is. It's the infrastructure of the next software revolution.
You can bank on open source AI taking over unless the EAs and the doomers manage to regulate open source AI out of existence (they almost certainly won't, thankfully).
Proprietary software just can't compete with open source long term because there are only so many people those companies can pay to work on their software no matter how deep their pockets. If you had all the money of Microsoft, Oracle and Intel back in the 1990s you could not have created the Linux kernel and matched its nearly 1M contributors.
The same will happen with AI.
Soon even a large team of AI researchers won't be able to out-compete the massive open source swarm.
3. We'll probably hit a wall with how much more we can squeeze out of new LLM models, without new techniques. GPT 5 will likely be only a bit better than GPT 4 ( again, without new techniques).
This one flies in the face of the last prediction a little but go with me for a moment.
Notice I repeated the caveat "without new techniques" twice. Researchers are always working on new techniques and a breakthrough here would change the trajectory of this prediction and likely make it wrong but without a breakthrough we've probably hit a wall and new models will be only marginally better, not massively better.
The main reason I think we're hitting a wall is Gemini.
Gemini Ultra largely failed to surpass GPT-4. It's evolutionary, not revolutionary.
That's shocking and points to a bigger failure because Google had every reason to make Gemini revolutionary and crush Open AI.
They failed.
The problem is that if an organization like Google with all the money, compute, research talent and data in the world can't build a better model than who can? It almost certainly means that we've run out of room with the current techniques and that we've likely hit a plateau in what the current architectures can do for us.
This is really surprising because the hype leading up to Gemini was fantastic and presaged great things from the model. Google issued an all-hands-on-deck battlecry for AI, mentioned AI 140 times in their developer conference keynote, and unified Deep Mind and Google Brain under one roof.
Google brain mastermind, Demis Hassabis, said Gemini would beat GPT by "tapping techniques learned from the [very impressive] AlphaGo" in the run up to the release.
So what did we get?
We got a paper and news blast PR blitz with a sizzle real and branding documents. They touted the superiority of Gemini Ultra but still haven't released it and instead dropped a sub-par GPT 3.5 level model.
Even worse, they invented their own dubious benchmark to even show a fraction of better performance than GPT 4 on their still unreleased Ultra model (so nobody can actually verify this yet) and they released a faked demo video that was amazing but ultimately bullshit.
We're still waiting for the GPT 4 level model.
What we wanted was a breakthrough with Gemini. We wanted a logic and reasoning powerhouse that never hallucinated and easily used outside tools the way people use their arms and legs.
We wanted a big leap over GPT 4, not an on-par model that basically cooks the books to look only marginally better.
It's been a year since the release of GPT 4 and we're still waiting. And waiting. And waiting.
That doesn't mean there is nothing left to squeeze out of these models and these techniques. Open source swarm intelligence will continue to refine and polish these techniques to perfection over the next year and that's awesome. But it means just hurling compute and data at models will not be enough to give us the next big leap we're looking for right now and it won't magically lead to superintelligence.
As I've said in my take on Richard Sutton's Bitter Lesson, scaling and general purpose techniques (like back prop, RL, genetic algorithms) almost always provide the best bang for the buck and produce the biggest breakthroughs again and again in AI/ML despite all naysayers. So at one level scale is all you need but on another level you need the right general purpose technique for that scale to matter.
And in this case we likely still need a new general purpose technique and a lot of GPUs going brrrrrrr.
To get where we really want to go we will need what Yan LeCun always says we need, some new stuff we haven't thought of yet.
4. We'll see a much stronger focus on synthetic data and alternative training methodologies.
This follows naturally from the last prediction.
We need something more.
Somewhere out there is a smart, self-taught researcher with a white board working on a universal learning technique and that's what we really need to get to AGI.
But in the meantime, synthetic data or a new kind of learning method would go a long, long way.
Synthetic training data is machine generated data. We're already at the limits of what data is available to scrape unless we start scanning every single book and page in history and even that has a limit. Media companies are also doing their damndest to make this process much, much more expensive. GPT 4 is effectively trained on the vast majority of the Internet and a large corpus of non Internet data too.
The data scientists know this and they are working hard to overcome it.
There is speculation that OpenAI already overcame this limitation, though I'm still skeptical until we see it. As Bindu Reddy, CEO of Abacus AI, wrote during the Open AI drama, much of the fears of the OAI board that caused them to try to oust Sam Altman allegedly revolved around a new breakthrough from Ilya Sutskever that supposedly overcame the limitations on getting high quality training data.

If they really have solved the synthetic data problem, it's big.
If I want to train a model to detect boat crashes, I likely don't have enough footage to make a good model. But I can generate synthetic examples with a game engine like Unreal 5 and then train an awesome model.
But when it comes to the data that LLMs need, high quality, well written human writing, synthetic data often falls woefully short. It's also terrible for things like fraud detection models, because the synthetic data generator just won't output any novel fraud techniques for the model to learn from, just variants of known techniques. You need devious human to come up with new fraud for the model to learn from.
All that is to say that synthetic data is super tricky. Anyone who solves it mean they don't have to deal with any absurd lawsuits from the New York Times and others who want to AI companies to pay a massive licensing fee for training data.
If it's not data than it will likely be advances in techniques that mimic how we teach children. Check out some of the advances in reinforcement learning in the below video from Google's work on robots.
In the video robots learn to play soccer basically "on their own." They're given the rules of the game and some motion capture videos on how to walk and kick but they need a lot less training data and then they go to work experimenting the way a toddler might experiment with kicking a ball around the back yard. They don't need massive amounts of training data, just their own experience. This technique also worked incredibly well for game playing models like AlphaGo and AlphaGo Zero.
AlphaGo Zero was the successor to AlphaGo, the platform that beat Lee Sedol. AlphaGo included a great deal of human knowledge baked into it. It learned from human games to build its policy network. It had a ton of glue code to write around problems.
But AlphaGo Zero used no domain knowledge, just pure generalizable learning.
Zero knew nothing about chess or Go or other games except the basic rules.
Play. Learn. Evolve. Reward. Punishment.
AlphaGo beat Lee Sedol 4-1.
AlphaGo Zero beat AlphaGo 100-0.
I covered Raia Hadsell's work on robotics at Deep Mind back in 2022, with an article called The Coming Age of Generalized AI with her earlier work on combining techniques like transfer learning, overcoming catastrophic forgetting, weights averaging and continual learning. Basically her approach was to train a small neural net on new tasks and the download the weights into a much bigger existing neural network to upgrade its skillsets. Think about a robot that can download how to do the dishes, while maintaining its ability to iron clothes, and you've got it.
If this kind of approach works, then you just have a massive and minimally trained neural net you merge new skills into continually. All you need is the updated skill pack of weights that get averaged into your existing robot’s neural network and voila, you now have a dancing robot that can do the dishes and fold clothes and then tomorrow it can download how to walk the dog.
The breakthrough could also come from the fabled Q* (pronounced Q star) technique that Open AI researchers used to dramatically improve a model's math capabilities which caused researchers to write a letter to the board about its potential for AGI before the Sam Altman debacle.
And even if it's none of these techniques, it's only a matter of time before researchers come up with new ways to train AI that makes the current methods obsolete or less important, which means this entire attack on training data is an utter and complete waste of time that will not stop AI.
That will leave copyright holders with no leg left to stand on. They will lose what little leverage they currently have over AI companies and have to go to them hat in hand to ask them to link to their content via Retrieval Augmented Generation (RAG) because everyone will have an AI assistant that they ask questions to first before looking the answer up themselves.
At that point AI companies will play king and queen maker with media, choosing who to link to and who not to link to and I suspect that revenge will play no small part in the negotiations.
5. A non-transformer model will make tremendous headway, making context windows largely irrelevant and making inference much more efficient.
We've already seen big progress in 2023 with non-attention based models, in particular StripedHyena and Mamba (awesome name). Nathan Lambert covers some of the alt model contenders here on his blog.
The Mamba model is particularly awesome in that it seems to use 4X less compute for inference, scales linearly, and can reach context windows of over a trillion tokens (versus the 8k, 16k or 32K of most of today's models). That is a massive trifecta of features. But of all of these, the context window is a particularly awesome improvement because context windows have always felt like early RAM limitations on computer games to me.
And I'm sure the sys admins in charge of scaling inference will like the 4X less resources even more and so will businesses and their bottom lines. Compute is very, very, very expensive and the current state of the art models are a beast to run in production so anything that cuts the cost to run them, while maintaining state of the art performance, will be readily embraced by companies and researchers.
Context windows in current models are also not all that good. It's not just a matter of making them bigger with fine tuning or other hacks to the model. Research in the paper "Lost in the Middle: How Language Models Use Long Contexts" showed that models tend to focus on the beginning and end of the text and get lost in the middle. As Matthias Bastian wrote in the Decorder article on the paper: "The researchers tested seven open and closed language models, including the new GPT-3.5 16K and Claude 1.3 with 100K. All models showed a more or less pronounced U-curve, depending on the test, with better performance on tasks where the solution is at the beginning or end of the text."
We really, really need a new architecture to address these things because most of the approaches to fix these limitations are basically hacks that paper over the problem without really solving it. People forget that Transformers and attention have been state of the art since 2017 when the Attention is All You Need paper came out.
That feels like a 1000 years with the current AI development pace.
Time for something new and hopefully 2024 is the year.
6. Agents will become much more ubiquitous and proficient at completing complex tasks.
The real goal of AI is not to talk with it but to get it to do complex, long running, open ended tasks in the real world.
There are a lot of good people working on agents right now and a lot of research looking to make them work better. I expect to see big progress this year.
While I don't expect we get to systems like we have in the movie Her, I do think we get much more capable systems that can book airline tickets, shop for us, keep track of hiring, do live narration of video games, analyze legal documents and much, much more.
Take the research Agent we wrote for the AI Infrastructure Alliance (AIIA). We fed an Agent a list of 1000s of curated companies from Airtable, had it go out and read the websites, summarize them, and then rate them based on how good of a match they were for joining AIIA as a partner. It was about 95% accurate, probably more accurate than an intern just learning the business and trying to understand what everyone does without having the background technical knowledge to make the call right.

Half a year ago, we couldn’t write that application. Sure, we could hack something together with some awful heuristics, maybe by taking the first sentence of every paragraph we found on the page but there was no intelligence behind it. It wasn’t smart. It’s now trivial to write an almost fully autonomous Agent to do this and we did it in a few days.
Agent style applications are complex but so far they have fallen short. They require reasoning and planning by the LLM and early attempts like AutoGPT often allow the LLM great freedom to make all the decisions without any check or balance so the agent usually just went off the rails and got it wrong. It's a bit like those old long division problems. You got the first step wrong and so the next fifty steps are wrong. But as we get better reasoning and planning from researchers, we'll get better agents.
We're already seeing some great work on getting models to do tasks better and that will only benefit these future digital workers. One of my favorite papers of 2023 was Agent Tuning: Enabling Generalized Agent Abilities for LLMs. Basically they fine tuned Llama 2 on a diverse array of tasks like clicking around a website and ordering tickets and were able to make massive improvements in the model's ability to complete entire tasks rather than screwing up half way through.
On the ALFWorld dataset, which is a text based dataset of problems that remind me of the old Choose Your Own Adventure (R) books (kind of like video games in book form, before video games existed), the 70B model went from 6% accurate to 86% accurate. That is a massive and dramatic improvement.
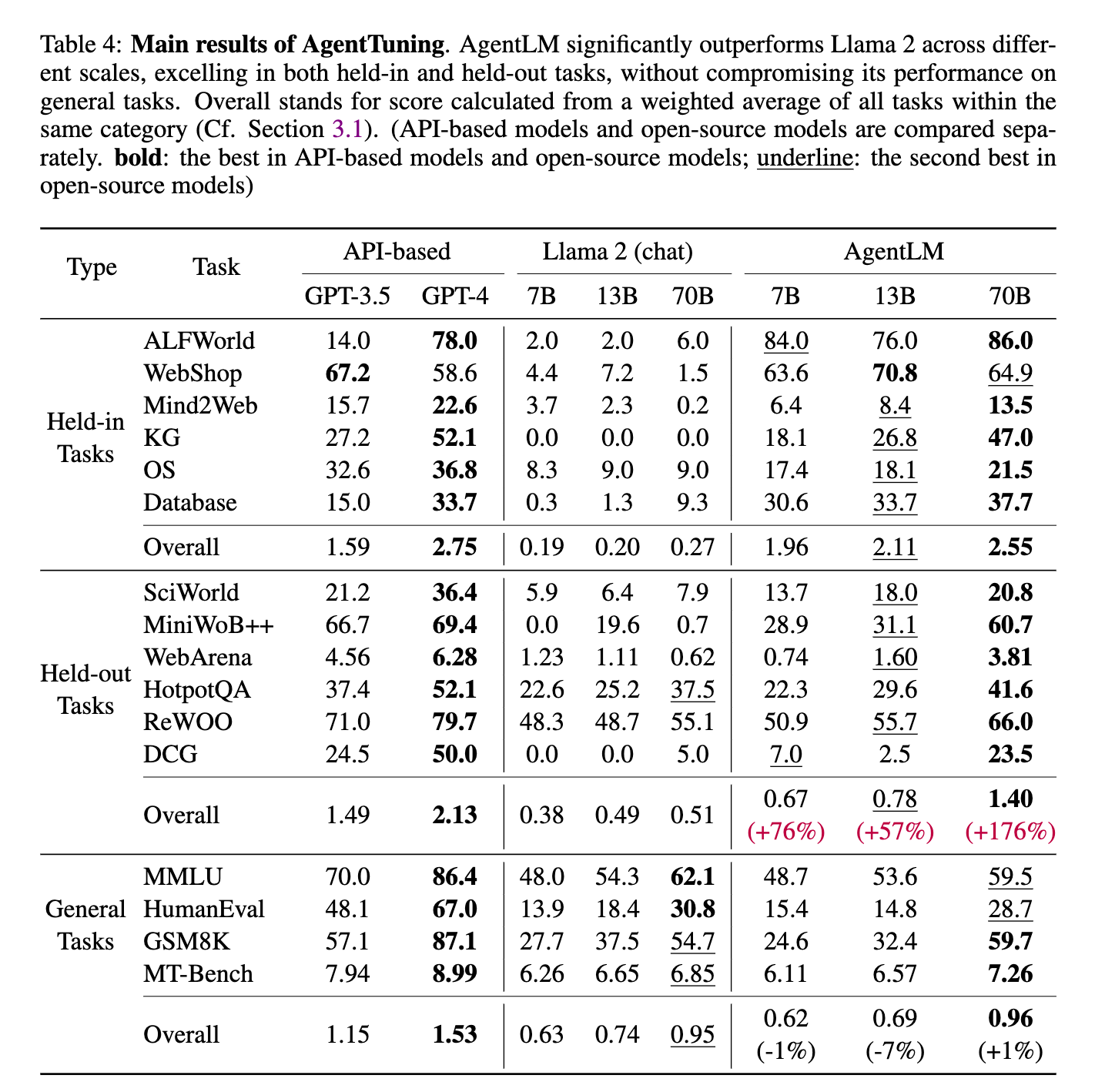
(Source: Agent Tuning paper)
Expect a lot more models fine tuned for tasks this year and a lot of agents that actually start working and becoming very good at enhancing your daily life.
Meanwhile, the models will also get better at using tools to help them do things. The Hugging GPT paper was my other favorite paper. It models the way I see most agents developing over the next few years.
The HuggingGPT approach uses HuggingFace’s vast descriptions of models as a way for LLMs to figure out what each model can do. With those text descriptions it was enough for GPT to figure out what task specific model it could call to do a particular task, such as “please generate an image where a girl is reading a book, and make her pose the same as in the example.jpg, then please describe the image with your voice.”

(Source: HuggingGPT paper)
In this case the agent does the complex reasoning that might be hard coded in a more consistent and limited workflow design pattern. This ultimately involves several different models to do that work. We can see from the graphic that it uses OpenCV’s OpenPose model that extracts a skeleton like outline of a pose from an existing image, then use a controlnet model (which injects that pose into the diffusion process along with the text description from the user to get better outputs), an object detection model, detr-restnet-101, a vision transformer image classifier model called vit-gpt2-image-captionin, a captioning model called vit-gpt2-image-captioning to generate the text caption, and a text to speech model called fastspeech-2-en-ljspeech to give voice to the text.
Essentially this involves four core steps:
Task planning: LLM parses the user request into a task list and determines the execution order
Model selection: LLM assigns appropriate models to tasks
Task execution: Expert models execute the tasks
Response generation: LLM integrates the inference results of experts and generates a summary of workflow logs to respond to the user
As you might imagine this is an incredibly complex pipeline where results may vary dramatically. It is also something that was literally impossible to do even a year ago, even if you had $50 billion dollars and a small army of developers because there was no software capable of this kind of automatic selection of tooling based on complex natural language instructions from a user.
Putting this kind of pipeline into production will require a suite of monitoring and management tools, logging, serving infrastructure, security layers and more. These kinds of applications will form the bedrock of new kinds of software apps in the coming years.
While I expect new approaches to present themselves with time, I think the basic design pattern of these applications will remain much the same through 2024 and beyond.
LLM + outside knowledge repos + DB + code + specialized models.
LLMs and specialized models working together will be the heart of agents in 2024 and for the foreseeable future and 2024 will be the year they start to get really useful.
7. The US and UK will do what they always do with legislation, focus on commerce and business instead of arcane and overreaching rules.
While the EU regulators do what they tend to do, write lots of pages of legalese long before there is an actual need or an actual problem, American and US legislators tend to talk tough and then just fall back to promoting business and commerce.
Even the EU will scale back the AI Act because for the first time in decades they have a chance at having some of the top software companies in the world and their economies and leaders desperately need that win. A company like Aleph Alpha or Mistral can finally make the EU a powerhouse in software as long as they don't strangle their own companies with mountains of legislation.
The EU AI Act is a solution in search of a problem. It will create months or years of bureaucracy for AI companies and it has provisions that are hard to enforce and probably impossible to do in practice and counterproductive too. For instance the act calls for watermarking AI content.
OpenAI already tried and gave up on watermarking text because it's pretty much impossible.
Also why even bother?
If I write something and have AI correct my writing is that AI created? Do I need to label that?
What if I have the LLM generate an article and I only keep 30% of that and dramatically alter it? Is that "AI generated"?
Should I have edits from from editor in my articles labeled too?
This is nonsense and it will create a frustrating quagmire for companies trying to comply with it.
Thankfully cooler heads are starting to prevail in EU AI Act negotiations and the member states are backing down from regulating the training and distribution of models. That's good. But there are still a lot of not so great ideas in these bills and in the Biden executive order that have bled into the language from fringe group lobbying efforts and mass media fear mongering, like required reporting on large training runs and the like.
Luckily executive orders are often challenged and killed in court and that is exactly what will happen here.
What kind of legislation will we get from congress, the only folks who can actually make laws?
Right off the bat, they won't want to look heavy-handed like the EU because that doesn't play well with American voters.
And historically American legislators almost always come down on the side of business, money making, and commerce and that is exactly what I expect to happen here, if they bother to pass any AI legislation at all in 2024. Considering it's a voting year, they might just punt on it all together.
The UK has already been touting that it favors light touch regulation of AI because it wants to become a global powerhouse in AI.
Every country wants this.
As Putin said back in 2017, the country that leads in AI will "become the ruler of the world."
Any country that passes overly harsh legislation will find their future industries stagnating while companies flee to more favorable jurisdictions and that will push them to scale back their ambitions to curb AI.
I expect that we will see data and training safe havens if countries overreach. Think of Singapore for business entities but for AI. Maybe Estonia or Ireland or the UK becomes that AI virtual factory? Someone will make it super simple to train and publish AI.
Other countries might ban it but their citizens will cry bloody murder when they are cut off from the most important tools in the future while other countries get access to them.
8. The US and the UK will enshrine data scraping for training models as a legal precedent and the cases against AI companies will come to a crashing halt.
This goes hand in hand with the last prediction.
Pop quiz:
Who do the biggest superpower governments on Earth choose here?
AI, aka future of all major commerce, power over rival superpowers and the key to continued military superiority
The math is not hard to figure out here and I suck at math.
The underlying invisible economic forces will drive this in only one direction for the major powers of the world as inexorably as the moon drives the tides. The legislators and courts will come down on the side of the future.
Most of the cases will be settled out of court anyway, because this is not really about enforcing existing copyright law. It's about getting some extra money, even if on the surface it's framed as copyright.
The negotiations for how much money the New York Times wanted to get paid versus how much OpenAI wanted to pay them broke down and so the NY Times launched a case. As quoted in the NYT itself "Gannett, the largest U.S. newspaper company; News Corp, the owner of The Wall Street Journal; and IAC, the digital colossus behind The Daily Beast and the magazine publisher Dotdash Meredith — have been in talks with OpenAI, said three people familiar with the negotiations, who requested anonymity to discuss the confidential talks."
The goal is to settle out of court and get a good chunk of cash, not to actually take it to court in a long drawn out battle.
Many artists and copyright holders are putting a lot of hope and faith in these cases to protect them from AI but it's just not going to work out the way they hope, so they are much better off looking for a different track here or adapting their workflow to embrace AI as just another tool in their tool belt.
Let's say they do win though. There is no doubt that opponents of AI can manage to make it painful for a time if they win.
And that can create a world where copyright is expanded in new and ugly ways. Artists who are cheering for wins over training data don't realize they are cheering for restrictions on their own rights and for the rights of one big company over another, not individual artist rights. They are cheering for AI to be much more expensive because the costs will get passed down to you and me and your children.
Take something like Paul's Boutique. It used to be perfectly legal to sample and then big copyright holders got their claws into things. Today you couldn't make Paul's Boutique without 20 million dollars and probably more like 40 M today with inflation.
If folks really stopped to consider all the repercussions and unexpected consequences they might not like the world they're hoping to create, one where big content providers can restrict whatever you want to write about or paint or draw.
What's really happened here is that big content providers have capitalized on artist rage and fear and duped them into supporting copyright expansion.
There's a sense in the artist community that every artist will get paid for their training data if they rally behind consent.
Let's be clear. That will never happen.
Nobody is ever calling up Dan Jeffries and sending me a check because they scraped my Future History Substack. Maybe Substack, the corporation behind my blog, might try to charge for their API but I won't ever see a dime of it, guaranteed, or if I do it will be pennies on the dollar from Substack itself if they're feeling particularly generous.
So who will get paid?
The giant content companies that you already signed your rights away to years ago when you weren't reading their T&C's.
It's a gold rush right now as content companies everywhere, who've been paid handsomely by ad revenue for decades, are now licking their lips at the possibility of soaking up some new revenue from AI companies.
Reddit is demanding payment for its API to AI trainers and StackOverflow says they will too. Others will follow. Elon Musk threatened to sue Microsoft for "illegally" training on Twitter data. Let's be clear. There was no illegal anything. Elon is just making up a new law in the court of public appeals because he smells a new way to monetize his multi-billion dollar purchase of Twitter. He and everybody else.
Scraping that data was absolutely fair use. Case closed.
They can change their terms and conditions but there was nothing illegal about it. They can change the rules for how people can use their API too but someone can still scrape their publicly facing website. That's why Twitter crushed your ability to read any tweets without signing up now and for no other reason. You used to be able to read a twitter thread without logging in only last year. The law can change but until it does, web scraping is legal and continues to be legal as many court cases have affirmed.
Even if one of these suits win, and it's a super long shot, the reprieve they buy will be short lived for several reasons we already talked about here.
Agents
Synthetic data
Alternative training methods
While media companies are hoping to squeeze dollars out of AI model companies, that money would only equal a fraction of their revenue. Their real revenue comes from people consuming their content. Actually it doesn't even really come from that. It comes from the ads people click on the page usually, which ironically drives people away from their content, unless the media company has a subscription service.
And this is an Achille's Heal once AI agents take off.
Because the second that I have an agent that can go fetch and read the content for me I will never go to that page again. I will never go to the ugly recipe site and endure a full blown ad sensory assault when I just want to learn how to make a nice cassoulet for dinner.
This will kill off much of the business model of the current web and something else will evolve in its place. I don't know what that model is but rest assured that it will emerge. If anything, people are remarkably good at figuring out how to get paid for things and a new business model will emerge because it has to and necessity is the mother of invention. On second thought, maybe this may bode well for folks cheering for the NYT in their lawsuit, but revenue from AI companies won't be even close to enough to replace people going to websites and clicking on ads so we need something else.
The second two reasons are closely related, synthetic training data and alternative training methods and we’ve already talked through them earlier so I won’t reiterate here. But know that they both hold the possibility to dramatically lessen the need for more and more expensive training data.
Ironically, an unlikely win by media companies would actually accelerate the race for alternatives, just as early bans on stem cell research caused researchers to figure out how to take ordinary cells and turn them back into stem cells rather than harvesting them from fetal cells.
9. Governments will continue to carve out exemptions in their regulations for the most dangerous uses of AI, namely lethal autonomous weapons (LAWS) and mass surveillance, and nobody will notice.
With X-risk sucking all of the air out of the room, we've gotten away from talking about real AI risks and dangers.
Somehow we've gotten to worrying about absolute nonsense like AI turning us all into paperclips, meanwhile autonomous killing machines, aka LAWS or Lethal Autonomous Weapons are moving ahead at fantastic speed totally unchecked. Those are for real dangerous. Lots of governments are building them anyway and they will continue to do so.
Why aren't we talking about limiting these kinds of systems? We're simply not seeing government legislation to protect us from nation states using AI for spying, mass surveillance and lethal weapons. Instead we're seeing legislation focused on the private sphere, aka you and me getting to use AI. Governments are all carving out exceptions for them to use AI in national defense, aka for however they see fit, in whatever way they want to use it. This is not speculation, this is actual fact in both the Biden order and the EU AI act.
Ronja Rönnback writes "While the AI Act prohibits or sets requirements for AI systems put on the EU market, it explicitly excludes from its scope AI systems used for military purposes only. Council’s General Approach on the AI Act confirmed this exclusion by referring to systems developed for defense and military purposes as subject to public international law (also according to the Treaty on the European Union, chapter 1, title V)."

(Source: The Economist's cartoon about the EU AI Summit)
Instead of worrying about war weapons and mass spying, we worry about whether ChatGPT makes up wrong answers to questions, as if it's the same thing. It's not. If kids use it to cheat in school, it's somehow a national disaster and the subject of countless news articles lamenting the death of education. Here's a shocker, kids have been cheating in school for all of time. Smart teachers are already adopting and embracing AI as something to learn about for tomorrow's workforce reality where everyone uses AI, rather than knee jerk reacting to it and banning it as if they could ban it anyway.
If we're not careful, we'll end up with big restrictions on civilian AI while governments can use it for actual evil uses cases with impunity.
Hopefully, I'm wrong about this one and 2024 is the year everyone stops talking about nonsense risks and starts worrying about real ones.
Whatever Happens, It'll Be Wild
2023 was already one of the wildest years I've ever seen in technology and I've lived through a lot of techno revolutions in my lifetime. The pace of development in AI was explosive. AI is developing at incredible speed.
It's hard to believe the difference between Midjourney prompts a year ago and today.

(Source: Reddit / Midjourney)
But the unbridled optimist about AI has given way to larger fears and the technology has become a battleground. This is no surprise really. Every technology, throughout all history, faces backlash and challenges.
As Isaac Asmiov wrote, every new technology faces resistance, from coffee to the printing press to cars.

Take coffee as an example technology that faced major blowback in its time.
You might not think of coffee as a technology, but the process of gathering the beans, roasting them, storing them and transforming them into a drink are all part of a chain of technologies that make it possible for you to get your morning caffeine fix. Today, when you're picking up your coffee from the local hipster barista shop or mega-chain you probably never imagined it was once controversial.
But for hundreds of years it faced slander, demonization, legal attacks and more.
Kings and queens saw coffee houses as breeding grounds for revolution and regularly shut them down, harassed owners, taxed and arrested them. In parts of the Islamic world many powerful leaders saw coffee as an intoxicant no different than alcohol and drugs and they attacked it on moral grounds (same story, different day) with fatwas.
Beer and wine groups formed powerful opposition groups to coffee, seeing it as a competing product that encroached on their market share. For the vast majority of history people didn't drink water because it was tremendously unsafe, but they did drink beer and wine that was watered down throughout the entire day. Beer and wine makers saw coffee as destroying their markets and fought it tooth and nail.
If all this sounds like the battle between media companies and AI companies that’s because it’s an exact mirror of it for the modern world. The pattern is the same throughout all history, again and again.
What they were really arguing about was power.
Coffee houses were places where people got together and exchanged ideas and that was dangerous to the kings and queens of old who thrived on keeping people locked down and ignorant.
Competing businesses saw it as a way to eat into the profits and that was about jobs and who gets to make the money. Both forces fought back against the society-shifting power of coffee.
You already know the story of how the prohibition of coffee turned out.
Spoiler alert, AI will work out the same way.
The pattern is simple and eternal. New technology comes out. Moral panic and backlash ensue. Entrenched powers fight back. They win for a time and stop the bleeding only to lose badly later and die off in a flurry. People adopt the technology because they love it. It becomes a part of their lives and eventually they just use it and never think about it and nobody even remembers there was a war over it.
Today most people would look at you like you had two heads if you told them coffee was once a battleground. They're taking selfies with their coffee and getting it to go to work or study harder.
After a technology triumphs, the people who come later don't even realize the battle happened. To them it's not even technology anymore. It's a part of their life, just another thing. They just use it. To someone born today, a car or refrigerator or a cup of coffee is no different than a tree or a rock. It was always there.
The same will happen with AI, one way or another. It's just too important and powerful of a technology for it to not find a way forward. There is simply no industry on Earth that won't benefit from getting more intelligent.
The more people use it, the more they will realize how amazing it is and how much they want it in their lives. It's already happening. My step mother was using it to help with her writing and to spit out ideas about ideas for a raffle. My friend's five year daughter talks to the GPT voice interface in her native language and they create stories together.
2024 will be a year of battles and breakthroughs, a back and forth seesaw.
But a decade from now, kids will have grown up with AI and it will have been a part of their life, a constant companion and friend, the way it is to my friend’s daughter.
And if you tell them there was once a battle over it they will look at you like you're crazy and wonder what all the fuss was about.
These predictions make a lot of sense. They are more specific than many AI predictions I've read and each prediction carries huge ramifications to our culture.
The one major prediction I think you might have missed is with AI's recent advance in generating voices and likenesses, we will likely see a huge rise in identity theft and deepfake technology misuse blurring the lines between what is real and fake. This tech is now in the hands of the mainstream and not just media tech specialists.
Thanks for sharing, as crazy as 2023 has been, 2024 is going to be even more insane.
For those interested:
The examples with the uptake of coffee are copied from the book "Innovations and its enemies: Why people resist new technologies" by Calaestus Juma. (The 2nd chapter ). Great book, btw.