

The AI Powerhouses of Tomorrow
Who'll Build the Most Defensible Castles in AI and Who'll Build Castles Made of Sand? A Look at Potential Winners and Losers for UI/UX, Business Model and App Design in the Age of Industrialized AI


A lot of people are wondering who's going to make the big money in AI?
Who can build big, powerful defensible businesses around machine learning and fend off a horde of challengers?
Will it be the foundation model companies? The masters of UI/UX design? The open source AI pioneers? The big tech behemoths like Google and Microsoft and Facebook, with their small army of engineers? Or will it be a bunch of new companies that come out of nowhere to capture market and mindshare fast?
There are even more critical questions too: Will AI be open or closed? Are we rapidly retreating from open source to the closed retro-computing era of Microsoft and the Wintel dynasty?
Mostly people are asking the questions but the TLDR of these articles is nobody really knows yet.
That's true in many ways.
But we can start to make some strong predictions and I'm going to do that right here.
Or course, before I do I'll say what I always say: Prediction is a tricky business. Predictions can look foolish a decade later. In 1995, Clifford Stoll confidently opined in Newsweek that the web wouldn't amount to much and that people would never telecommute, buy books, chat, read newspapers or shop online. As you might imagine that didn't age well as we do all that and more on the web now.
As Yoda said, "difficult to predict, always in motion is the future." We might see a clear trajectory if things keep going the way they're going and then a black swan completely changes the arc of what's possible.
That's not going to stop me. There are some clear trends developing and we can start to use them to figure out where things are going over the next 5 to 10 years. But to get there, let's start with right now. Where are we with AI?
We're right about here at the "takeoff stage":
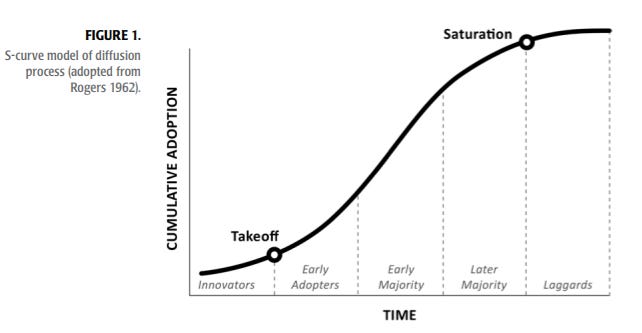
ChatGPT roared out of the gate and became the fastest application to reach 100 million users, doing it in just two months. Stable Diffusion made large scale image generation possible and was the fastest app to ever hit 10,000 stars on Github, rocketing to 33K in only two months. The venerable image diffusion model saw a massive community of apps and fine-tuned models spring up around it almost overnight.
There's something immensely weird about how quickly AI gets adopted now.
It's because there's almost no learning curve. AI is super intuitive to use.
That's different because older technology had a massive learning curve and that made adoption much slower. Think about the first time you tried to figure out all the buttons and menus in Photoshop before you could do anything even remotely interesting. Photoshop is immensely powerful but it's not something you can pick up and understand immediately. It's like learning Kung Fu. It takes time.
But when it comes to AI, we already know how to interact with it. We've trained our whole lives to talk and ask questions and give verbal commands. We talk to LLMs like ChatGPT as if we're talking to another person.
A perfect example happened to me just the other day. I was a sys admin for a decade so I got pretty good with Bash scripts but I'm mostly out of practice these days. I was doing a Stable Diffusion fine tuning project and I wanted to create a bunch of text files with the same name as the image files so I could write the labels for each image. I knew I could write the script but that I'd probably spend a half hour digging around forums trying to find the right regex or the right syntax for sed and awk to slice and dice text so I was avoiding it.
Then I remembered I could just ask ChatGPT.
It spit out the script on the first try. Even better, it documented it.
Then I asked it to modify the script 4 or 5 times with new ideas I had, like adding support for PNG files and files named jpeg instead of jpg, as well as echoing everything before the dash into the text file and putting a space between any capital letters in the echoed text.
Of course, ChatGPT is prone to hallucinations from time to time and sometimes sounds really confident while being totally wrong, but code is easy to test and I was able to check that it worked with just a few modifications before running the script for real.
If that's not amazing and intuitive I don't know what is.
It feels like magic.
In a way it is magic.
As Arthur C Clarke said, any sufficiently advanced technology is indistinguishable from magic.
We're rapidly entering a time where we can talk with our computers, where AI becomes our interface to the world. It reminds me a bit of the way the Joaquin Phoenix talks with his "OS" in the movie Her or the way Star Trek characters talk to their computers.
Maybe someone can kindly link ChatGPT up with the lovely Scarlett Johansson's voice using Stable Voice?
Don't get me wrong. We're not at Her or Star Trek level capabilities and there's a ways to go to get there.
But we are getting to the point where we can describe what we want and more often than not get the machine to do that thing.
It's not hard to image just typing in the bash script description we want right from the command line and it executes that script. Someone already built a prototype of that with ChatGPT.
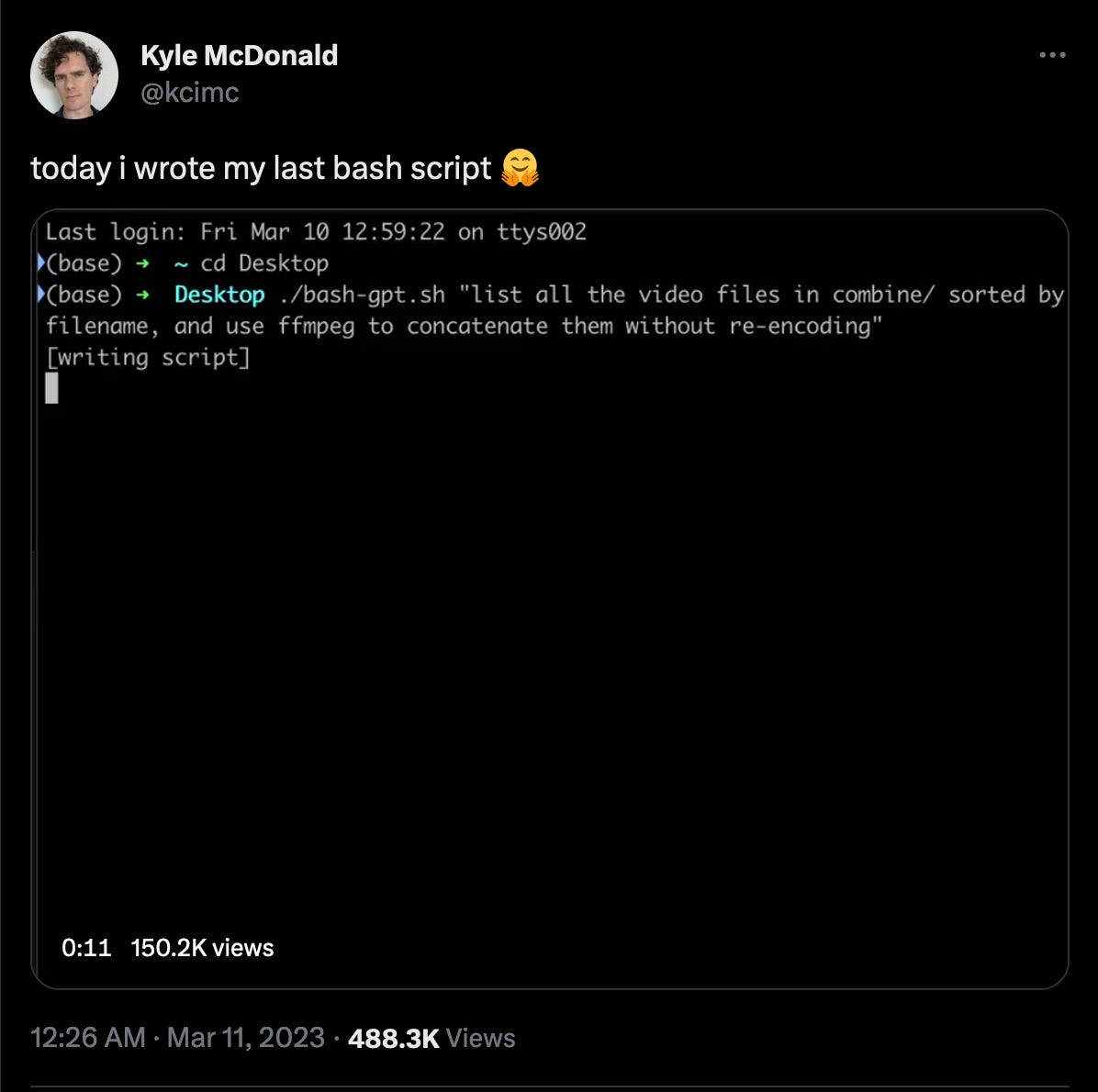

Again, it's not hard to imagine a more advanced form of this where you use a "--test" to simulate the output, and other advanced guardrail and editing features, rather than just letting it run and potentially damage your files with an unexpected "rm -rf".
AI can already do really useful things right now despite naysayers who constantly point out the technology's limitations as if it's useless. Maybe it's useless to them because they want it to be perfect but I just used it to save me an hour of crappy and frustrating coding and so did Kyle McDonald. While many naysayers gleefully point out what these systems can't do that doesn't mean they are not incredibly valuable and fun to use. They get more and more capable every day and they’re well beyond stochastic parrots at this point even if they still do stupid things sometimes.
We can use it right now to do really, really useful things that would have impossible only last year.
So let's dive in and look at who the potential winners and losers are going to be accelerating AI race and what kinds of software and advances we really need to get AI into the hands of billions of users.
AI as Interface to the World
To start with, one of the big questions is whether the rise of conversational AI and generative systems will give us brand new interfaces or whether they'll meet us where we already are right now?
In other words are we looking at the next generation of programs built from the ground up or are we just going to have plugins in existing programs and apps?
Take a look at a screenshot of this app from AMAI.

The app generates realistic voices that you can use to read novels, short stories, ad copy, presentations and more. They've got lots of different voices and even better, they have nine different emotions. Reading a story without emphasis or emotion just makes for a flat and boring read that sounds synthetic. A good voice actor will know where to put the emotion and the passion in any story. They may raise their voice or make it deeper at a key turning point or act out the dialogue like a one person play. We intuitively feel when the emotions are right where they should be when the speaker evokes the fear and passion in the story.
Their interface lets you highlight words, sentences or paragraphs and change the emotion, so the reading comes across dynamically. It's a bit like art directing the reading. An author is likely to know where the emotion should come in because they wrote it and this interfaces gives them the ability to direct the AI reading at a granular level.
That's a good custom interface that does a real service. But the question is whether it needs to be its own interface or if this is better off as a plugin to Google Docs or Word or Evernote? Both seem possible at this point.
On one hand it's easy to imagine a brand new Concept Art Studio in a box, a program that takes artists all the way from sketches to fully realized concept art to 3D. It does all the painting and sketching we've come to expect from today's tools but easily integrates AI endpoints to do automated steps along the way.
On the other hand, we already have really advanced tools like Photoshop, Painter, Maya, Blender, and Figma with decades of refinement so why not just extend them with AI capabilities? People have already invested the time and effort to learn them so it makes sense to meet people where they are now.
Time will tell. But here's how it's likely to play out.
In the short term, it makes total sense to build plugins. These software tools are venerable and work well so why reinvent the wheel?
A number of teams are coming up with excellent Photoshop plugins for things like Stable Diffusion, such as this one, and this one, along with Blender plugins and Figma and more.
When it comes to ChatGPT, Compose AI bakes it into a browser so you can use it anywhere on the web.
More and more I want the conversational apps that are coming out to meet me where I am. I don't want to use ChatGPT Pro just in the limited interface that Open AI built. I want it right on the desktop. I want it to be able to analyze text in any program, whether that's Gsuite, Word, notepad, Sublime editor, or Evernote. That's the concept behind open source apps like LangChain that is all about building composable LLMs that connect the LLM to any other app.
I don't want a separate plugin for all of the those programs that functions differently. I want to give it tasks like finding me a list of all the top generative AI companies in the world by searching the web and going to different articles and concatenating the list for me. I want to feed it URLs and have it summarize the text for me or tell me if the website is a scam. I want it to summarize articles for me and write replies.
Ironically that means a revival of the Siri and Cortana concepts that didn't really take off.

(Source: Microsoft/Cortana/Halo)
They didn't fail because they were bad ideas, they failed because the AI behind them was just not smart enough yet and the designers couldn't see beyond basic question and answering bots that were really no faster than looking something up yourself. Sometimes it goes like that in technology. Someone can see the future but the tech isn't ready. It took many refinements to make the steam engine work and to make refrigerators work without occasionally blowing up.
I expect to see companies bringing a universal conversationalists to the desktop that can move across any program with ease. Summarize my Slack for me and find answers in the Slack maze like Glean. Write entire emails for me like Google's new Gsuite AI. Go find me code in Github that does what I need now.
If I have a desktop AI interface that can write code, do searches for me, edit text, summarize websites and automate boring tasks for me then I've got a very, very powerful interface to the world.
At the same time, over the next five years, we're likely to see a hybrid of approaches. People will rush to bring AI to where we are now, extending existing programs but people will also build brand new tools from the ground up that incorporate advanced AI workflows as a first principal. The second approach will happen when it just doesn't make sense to easily weave AI into where we are now. We'll evolve new interfaces. It will be in places where the workflow changes what's possible and the existing metaphor of today's app just can't be bent or twisted to fit that new capability without it being awkward.
With all that said, the main problem with existing interfaces is that they might no longer be the right metaphor for interacting with AI and automating part of our work.
Take an application like Figma. They took many of the best ideas from Photoshop and Illustrator and refined them. They also build Figma as a distributed, web based application for teams to work together across the world. Doing that in Photoshop would have required a ground up rewrite of Photoshop, because it was born in the desktop era, before the browser and distributed teams. We're likely to see something similar to that happen with AI. As white collar workers everywhere get more comfortable with AI and what it can do, and that will demand new interfaces, written as AI first.
It's not hard to imagine a Conceptor program that's a fantastic mashup of Painter, Figma, Photoshop, Invoke AI and Blender. Right now, we have artists rapidly shifting between tools like Figma, Illustrator, Photoshop and/or Painter into Invoke AI or Automatic1111 to do their work, when it should all be done in a single tool. It will likely all end up under one roof so you have a concept house in a box.

(Source: Author. Conceptor system mock-up with a mix of Invoke AI, Painter, Photoshop and original concepts)
It is no small feat to create these features. Photoshop and Painter have had decades to perfect them. But the good news is they’ve also had decades of cruft and technical debt.
Figma showed that a completely new tool can gain rapid market share, if it brings in concepts people want, such as simplified interface and distributed team workflows for people spread out across the globe.
A tool like that could easily consume AI endpoints that are really advanced AI workflows behind the scenes.
Take something like doing "turnarounds." That's the boring part of concept art, where an artist draws a cool character they created from 10 different angles. This is something that can be automated and people are already working on it. Simply build a pipeline with 10 poses pre-built in open pose in the background and use a ControlNet to feed the exact positions of the character to the system. You might have different pre-built poses depending on whether it's a creature with four legs or more, a flying vehicle, a robot, or a person.

These kinds of invisible workflows are the key to next generation interfaces. These AI systems won't just be a single model consumed in the background, but an entire series of steps, designed in a workflow generator.
We might have a system that does all of the following transparently:
Step 1: Generate twenty images
Step 2: Checks them against another model that looks for Cronenbergs (aka hideous images)
Step 3: Four images are Cronenbergs so the code throws them away and generates four new images
Step 5: Upscales all the images
Step 6: Fix any facial distortions
Step 7: Fix any hand/finger distortions
There are millions of possible workflows that might be created and that's where most people will interact with AI. They'll mashup models and codes into smooth workflows that can be published as inference endpoints that apps will consume easily.
Let's say you've got a pipeline transferring styles into video, like the Corridor Crew did to make their amazing anime video.
It starts with green screen video filmed, some fine tuning on faces and style and then processing individual stills. At the end you run it through some de-flicker to get rid of the nasty jumping around effect in diffusion videos. It works great.
Now imagine that ControlNet comes out a week later and makes it 10X easier.
That's actually what happened with Corridor.
If they had a pipeline system with steps that are hot swappable they wouldn't need to start over. They'd just bake Control Net into it as another step and drop a few other steps. Do it right in the same pipeline. Reproduce the movie again, this time with the simplified steps and a better result.
Many movies will have the chance to go through multiple revisions and style changes and AI level fixes before filmmakers settle on the final results. It won't be a single post-production pass, but a living post-production that can change multiple times and redo the whole movie on the fly.
Fine Tuning the Future and Training the Robots of Tomorrow
Now let's take a look at a training/fine tuning workflow.
Imagine you're the tech person behind a small animation and design studio. You've got 10,000 assets that you're going to fine tune a diffusion or multi-modal model on so you can rapidly generate assets in your own style or do something tedious and boring, like drawing turn-arounds.
The training workflow will generate the turn around model or the style model from existing assets and make it available to the inference engine we already talked about above, so that it can be picked up as part of the Conceptor interface.
Fine tuning is one of the keys to big value in the future.
When I see the images coming out of Dalle 2 Experimental (the next version of Dalle) and Midjourney 5 (the new Midjourney) versus 4, I don't see as big of a jump. The leap from Dalle 1 to 2 was massive and the leap from the original Midjourney to Midjourney 4 was even bigger.
But I see many of the smaller, fine tuned models from the Stable Diffusion community as already superior. There's no doubt that Midjourney 5 is stellar general purpose image generator, and some of the images people are creating are incredible, but when you put it up against a super fine tuned model, the fine tuned model often wins hands down or matches the quality.
Here’s a fantastic image from Midjourney 5.

(Source: Julie W Design)
That’s a beautiful image.
But take a look at something like Illuminati Diffusion for realism/fantasy or Protogen for photorealism or specific painting styles and the results are equally incredible.

(Images from Illuminati Diffusion, and Protogen models)
The community models are where the innovation is really happening.
Why?
Hand tuned, highly curated datasets. And the shift left from “data science” to “developers and engineers.”
Once engineers get their hands on something, they start doing things the original designers never imagined or intended. It’s data science versus “applied AI.” They mash up models and mix them. Most data scientists thought the models would collapse when they got mashed up but it was a natural inclination of engineers to try that move and it worked. One engineer I know mashed up 200 different Stable Diffusion 2 models and it made an awesome model, instead of turning to garbage.
Now when it comes to highly curated datasets the problem is one of scale and knowledge.
Foundation models are trained on massive datasets and those datasets are messy to say the least. Their images are poorly labeled. Dig into the LAION dataset and you'll often find labels that have little or nothing to do with the image itself, which means the model is learning the wrong things about what's in the picture. Here is an example:

That image is labeled “diabetes, the quiet scourge.”
It has absolutely nothing to do with what’s in that image and it doesn’t help the model learn any of the concepts there like fruit, a tape measure, a blood sugar monitor, diabetes or anything else really. The label might as well be Lorem Ipsum.
The models only seem to get their coherence by sheer brute force and the size of their datasets. It papers over the mistakes. With billions of images it's impossible to properly label those images manually. Nobody has the people power to label 5 or 10 or 100 billion images by hand. So it's done with a combination of pulling metadata or programmatically via a model like BLIP2, which is data science in itself.
Models like BLIP2 are making it easier to get large scale labeling done but they're still not perfect. GPT-4 showcases some powerful abilities to know what's in images too meaning labeling large scale datasets might become a problem of the past.

By the way, understanding "what's going on in a photo" was an AI problem that was listed as "nowhere near solved" in 2021.

We can now move the problem to "real progress" or "basically solved."
This may make it possible to label billions and billions of images or text passages much more accurately and usher in a new era of super accurate labels that turbocharge foundation models but it’s still a hard, distributed MLOps problem. And it's also still very possible that these systems won't be as good as small, hand curated fine tuned datasets with baked in human level domain knowledge from experts.
Currently a model curated by someone who really wants to craft the perfect dataset and who hand labels them and infuses them with their own domain knowledge produces some amazing results and those results are much cheaper than training an expensive foundation model from scratch.
Even better, sometimes the foundation models themselves can spit out the fine tuning data, as Stanford proved with Alpaca 7B:
"[Alpaca 7B is] a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. Alpaca behaves similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$)."
The better the labels and the data, the better the fine tune. And even if big companies keep their models proprietary, the nature of their APIs may allows any team to piggy back off the models and generate enough synthetic instruct data right from the model itself.
But there's a problem.
Right now fine tuning and training is a massive pain.
Fine tuners are built on the back of low level MLOps tools that were meant to be all purpose MLOps engines. Most people will never interact with AI at this level. It's like writing assembler code.
Each new advancement in technology brings new levels of abstraction. You abstract up the stack. It brings in more people because we make it easier and easier to do something that was previous complex and that brings in more people who dream up new ways to use the technology that the original designers could never imagine.
We need tools highly specialized to training and tuning models only, accessible to regular folks, not pure engineers. We need a training revolution! We need to dramatically simplify the steps for that and give it an awesome interface that makes it smooth and simple. As much of the process should be automated as possible.
If you look at the various tools out there for training Stable Diffusion, they're almost universally terrible. Even the good ones, are basically too much setup and too low level and way too many steps. They're only good for hard core techies and even then it's a pain. Unless you're talking DreamBooth where you're just trying to train in 20 images of your face, it's awful out there. It's super overcomplicated.
There's absolutely no reason for it. Installing Python and libraries? Setting up a container? Writing steps in JSON? 25 step Colab notebook? It's just not necessary. Give people a pre-baked container behind the scenes with everything.
Step 1: Here's my images uploaded with zips and tar support.
Step 2: Automatically label the images with captioning model in the background.
Step 3: Open up a quick and dirty manual captioning system to check and fix those labels by hand and click start training.
That's it.
Unleash a training revolution. We can all teach our AIs. Distributed, decentralized training.
You can give people the ability to customize steps or drill down to advanced settings but most people will never need it.
A strong designer/engineer team could look at these 20 or 30 steps with current tooling and simplify it down to 3-5. 70% of them could be automated.
No matter what, these tools are coming and they are coming fast. And these tools will enable another suite of tools that consume their intelligent apps, embedding their intelligence as features or clusters of features.

Think concept houses in a box. Movie creators and rapid re-editors. Story editors and writers. Illustration and audio and music engines like we've only imagined until now. Talking to the computer and asking it what we want and getting it. Intelligence connected to everything.
We've never seen such a rapid uptake of tooling as software creators everywhere race to add AI capabilities to their software and new AI first companies are rethinking the interface from scratch too. The scramble to create the tools to support this scale is already underway, with the next generation of infrastructure companies already on the march.
But beyond interfaces, let's look at where the money really gets made.
Show Me the Blueprints - Show Me the Money
What kinds of companies are going to capture the most mindshare and revenue with their software?
Andreessen Horowitz's team asked a similar question on their blog:
Where is the value going to accrue?
Same places it always does.
Folks with the biggest scale. Companies with vertical integration. People delivering awesomely intuitive tools that do something people want and need now.
The cycle is the same every time, with nearly every technology in the modern world.
First the tech is broken and janky and it can't really solve real world use cases. People laugh at it or mock it. Then there's a breakthrough and a gold rush. We're seeing that now with Stable Diffusion and ChatGPT. Both of them captured hearts and minds and triggered an explosion of venture capital as investors put their bets down on generative AI.
Expect 3-5 years of 1000s of companies that are hard to differentiate. Many of these will be companies that put out a product that's basically a single feature with very little reason anyone would pay for it over the long term.
Take something like Lensa AI that was making millions of dollars a day. What happens when you've generated your avatars? You drop the app. You've got nothing more to stick around for so you leave.
If your company is making something that can be rolled into a larger app, or replicated by the big incumbents, you're going to get wiped out fast. Anyone who was making an LLM plugin for Gsuite or Office is now essentially toast. Microsoft and Google just wiped a dozen startups off the map by integrating state of the art LLMs into their apps.
That takes us to the next stage. After the surge of new companies comes the big collapse, consolidation and flame out. 80% of them will go to zero.
Maybe they're foundation model companies that didn't bother building a business and just thought they could keep getting people to fund them for eternity with no revenue or imaginary business plans, or maybe they're single feature apps that just aren't sticky enough for people to keep paying for them, or maybe the founders have a lot of vision but zero operations or business skill and so they crash and burn, or maybe someone builds apps that couldn't break even because compute is expensive and even though they built a good business they couldn't charge enough to make money.
There are lots of ways to fail at business and only a few ways through the eye of the needle to success.
But the companies that survive the culling will be the real players.
They have good products and good teams and a chance to win the big prize but they'll have to survive the rapid growth, keep their innovative culture and hold off their middlemen longer than everyone else.
They'll build those awesome products and then push into owning the entire lifecycle of AI. Maybe they made an awesome set of tools that everyone loves but they were dependent on someone else's models. They get rug pulled by the model company or the model company jacks their prices and slashes into their margins. They grit their teeth and secretly spin up the operations to train their own models, taking everything they've learned and doing it faster and better than their former model provider.
A lot of companies will start with foundation models that they grab via API but they'll build the best interfaces that capture the biggest audience and then they'll up-level to train their own incredible models.
A good company is not someone delivering a one-off use case. The best tools will do a lot of things that are valuable over time, something that customers keep coming back for again and again, like analyzing law documents, or copywriting for ads and blogs that's on brand and in the company style, or playing a never-ending stream of new music, or let's you rapidly edit images, or create and split test ads rapidly.
Right now, too many of these companies are basically a single feature. It's hard to justify that subscription price for something little. We want a lot for our money these days.
I found this company the other day: Autoregex. They trained a model to automatically generate regular expressions. Cool idea because regexs are hard to write.
If you're not familiar with regular expressions, they're basically incredibly powerful ways to filter, sort or change text but they're also notoriously cryptic and complex to write. If you could just explain what you want in natural language and the model creates the regex for you, that's a much more natural way to program.
When I first looked at the company they were charging for the service but it's since become free to use. It's not surprising that they went totally free because my first thought when looking at them was "this is cool but it feels like a feature in a larger program and I'm not sure anyone writes enough regexs to justify the subscription."
A bit later that very same day, I saw this tweet that shows ChatGPT analyzing a regex and explaining why it works.

If a big model like ChatGPT can already do this for free or as part of their larger subscription bundle, along with a lot of other things, which subscription are you going to buy? It's a bit like streaming. You're going to go with the smaller streaming provider if they have one show you really, really want to watch but you're going to go with Netflix or Disney or Hulu if you want tons of content for one price.
But I showed that tweet to my friend and she said, "But yeah I don't know if what ChatGPT wrote is true?"
That's the biggest rub on some of these mega language models. They're notorious bullshitters and they sometimes make up answers that sound great and but just aren't true. Sometimes that doesn't matter but it matters in code because even a single bracket out of place can cause the code to fail. I used to be pretty decent at regexes when I was a full time sys admin, but it's been years and I can't look at that answer and verify it without putting it into a bash script and testing it myself.
That’s when I realized that a suite lot of smaller, more finely tuned models that are much more accurate for a smaller subset of tasks might be the way to go for companies building a more comprehensive product suite. In other words, an ensemble for smaller, cheaper to train models.
It means that an autoregex model is better in a larger package of tools. It's not hard to image a suite of 20 or 30 coding tools that could be packaged up into a much more comprehensive coding platform that's incredibly useful to a lot of people, without some company having to train up a model on $5 million of compute.
A company doesn't need to train up a massive coding engine that does everything. They can train a regex generator, a SQL generator, a code annotator, a debugger, and suddenly that have a very compelling suite of products they can justify the subscription cost.
That also got me thinking about LoRAs, which I first discovered in the Stable Diffusion community. Check out this one that generates digital creatures. Instead of fine tuning a mega-model which can be slow and expensive and can even destroy the original model because it alters the weights, a LoRa basically freezes the mega-model's weights and creates a small micro-model that can dramatically influence the output of the original model. Think of them as small neural nets that piggy back off a bigger one. LoRAs were created by researchers at Microsoft to influence LLMs (Large Language Models) because LLMs can get super expensive to fine tune.
As the paper says, "Using GPT-3 17B as an example – deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive...Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times."
It turns out it wasn't too hard to adopt LoRAs to different kinds of models, which is why the Stable Diffusion community embraced them so quickly.
We're likely to see a mix of approaches for companies building products:
Giant do-it-all models like ChatGPT and GPT-4
Giant models with thousands or 10s of thousands of LoRAs attached to it
A string of smaller models directed by hand-written code that routes you to the correct model for the task that you're doing
A giant do-it-all model acting as the routing layer to smaller models because it understands the question and knows which model to pick to assist you
Smaller models also offer a good answer for alignment problems, fixing undesirable outputs and "bug" fixing models.
The baseline is big models that can do a lot of different things, packaged up with smaller models in the pipeline that help them fix different problems.
As companies build out these mini and mega-model streams and these new interfaces, we will reach the second collapse in the market, around the 7-10 year mark. Many of these companies will pioneer the right approach but flame out because of horrible management or terrible business practices or sociopath founders or getting outflanked by a smarter competitor.
The big players will battle it out but in the end, just a few will emerge, like a heavy weight champions that consolidates all the belts. The 50 players consolidate down to 5-10 players.
That's when the vertically integrated AI companies will truly emerge.
They’ll have the castle and the moat.

They'll have the models, the fine tuner/trainers, the massive inference scale that can serve billions and the end user apps that everyone loves and uses daily.
They'll be flanked only by the top of the line Foundation Model as a Service companies who basically offer intelligence as a service but even more importantly they offer piece of mind: Guardrails, logic fixes, safety measures, upgrades, rapid response to problems.
The three big likely winners are:
Foundation Model as a Service companies (FMaaS)
Vertically integrated companies that can do model training/tuning, have a killer end-user interface and mass adoption, and the ability to serve models at massive scale
Inference behemoths, think Akamai of inference
When it comes to Foundation Model companies, they’re the hardest to build and have the highest stakes. They’re expensive companies to run. They need big money, lots of smart and extensive people and supercomputers. It's easy to make the wrong choice about which models to create. Runway ML just trained up Gen-1 and Gen-2 and some of the early results are great. But the question remains, do we need a model that generates short video snippets directly, or is it enough to use a model like Stable Diffusion + Control Net + depth mapping + a de-flickering filter to go frame by frame and create long, coherent video? Time will tell.
Train the wrong model and you've just burned millions of dollars for something that folks will never use as they move on to other models that work better.
The model race will be long and bloody.
Making a misstep will cost people and crush companies.
As I noted in my earlier article, The Age of Industrialized AI, the people who crack continual learning will have a massive advantage in the FMaaS space. Any model that can keep learning new tricks without being replaced and that benefits from its previous knowledge will be a tremendous game changer and may create models that are motes for a decade.
If I have a model that's 100s of trillions of parameters and trained on 20 repositories of expensive private data then I may have a model that nobody can compete with until we have new few shot AI techniques that don't require much data and those new techniques take center stage and out-mode the old ways. It's not hard to imagine training AIs by example the way we train children or new employees or athletes. Researchers are out their working on those things now, but until those techniques become reality, data is king.
And until we crack continual learning and catastrophic forgetting, every model will be a singular way of looking at the world. Do you generate 3D directly or do you start from an image and then transform it to 3D? Do you make music via images of waves or do you try to learn the long term structure of music from wave files via transformers?
Each model will be a different approach to the problem and there is no guarantee that it solves the problem in the best way.
Once the model is baked there will be no way to change that approach without training up a new model from scratch. That's the promise and peril of training a model.
It's high stakes and high rewards but also really punishing to make a mistake.
If your model doesn't become standard than its basically dead and it represents millions of dollars of lost time and compute.
But make no mistake, there will be powerful FMaaS companies. Open AI is already well on its way there. Google has designs to be one too. So do many others. Someone will win and their models will power the intelligence revolution of tomorrow.
There is no big mystery here about how the long term trends play out. We start with 1000s and 1000s of little companies in a Cambrian explosion. Most of them will be worth zero in five years. But out of that primordial ooze will come tomorrow's tech powerhouses.
It will almost certainly be a changing of the guard. The AI masters of the universe will be new companies, not companies like Microsoft, Facebook, and Google. Make no mistake, those companies will make a lot of money from the new era, as their clouds will power inference and training at a lower level. Some may even make the leap to AI first companies.
But if you're expecting any of those companies to make the killer interface for model tuning and the combination Figma/Photoshop/Invoke AI/Blender end-user app that captures hearts and minds, then think again. It's not what they do. That's like thinking that TSMC will suddenly turn around and start making graphics cards, laptops and smartphones, instead of just making the chips that power those.
Those companies will have strong foundation models that power many applications but people will want open source models and alternative providers of intelligence. The big companies are too regulated, and too under the government microscope to provide the real flexibility that everyone wants.
They’re also likely to be too conservative.
Take something like Microsoft. They made a big splash rolling out GPT4 or whatever powers Bing search. But the were quick to neuter it when a few bad press stories broke. Microsoft's CEO Satya Nadella gave a great interview where he talked about how Bing was going to make sure the chatbot would still direct traffic to websites and not undermine the search business. Google will do the same.
But here's the thing.
Someone will come along who doesn't care about the search business at all.
They don't care about advertising. They find a different way to make money and then all bets are off.
The second I can have an AI tell me how to make a great pesto without having to go to that website I will do it and so will everyone else. Who wants to go to that crappy recipe website, with a hideous ad every other paragraph and three pop ups and the horrible EU mandated cookie annoyer?
Open and Closed AI
One last question we have to look at is the question of open versus closed.
We're going to see a push and pull between open and closed AI companies over the next five years. It's not a given who will win in the long run, although open systems do tend to triumph over the long haul historically.

Right now though, I'm really concerned that we're entering an era of closed software again, that hearkens back to the days of the Microsoft and Wintel dynasty, where open source was considered "cancer" by companies. We may be entering a time when everyone keeps their training data, models, parameters and architectures top secret.
The GPT-4 paper outright says they will tell you nothing about the model, not its architecture, not its training data, not how it was created, not its size.
"Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar."
Open AI's cofounder was interviewed in the Verge and asked about their past approach to openly sharing research and he said "we were wrong."
Open AI might be driven by fear of lawsuits like what happened with Stability AI and Midjourney, if they are too open with anything. They don't want to face a backlash and an expansion of copyright law that leads to a slowdown of AI development. They also seem to have lobbied congress members in their district to push back against open systems. All of this is a dangerous precedent that hearkens back to classifying encryption as munitions that led to totally unsafe browsers in the US that nearly made e-commerce impossible.
Closed versus open matters a lot. We could be heading back to an era of secret, closed source everything and that is a shame. Over the next 5-10 years I expect the battle of closed versus open AI to get fought anew. The way it plays out will have roots in history but also some differences. That's because developing AI software is currently very expensive. Whereas, a collective of great coders could get together and build great software for a big investment of time without a lot of money, it's not enough for a collection of smart data scientists and engineers to get together and spend their time alone. They need compute and data and lots of it and that is expensive.
Open source will likely follow some of the earlier patterns of open source, as a commodification engine. As models age and compute gets faster, it gets easier to train those older models on less and less hardware and that's where many open source companies and collectives will step in. There is likely to be a bleeding edge layer of proprietary models that is always ahead of the curve for the next 5 to 10 years but a flurry of older, open source models that are incredibly capable for many use cases.
So far open source models have gained massive ecosystem support and huge communities but the companies making those models have failed to capitalize on that mindshare, while smaller companies have used the open source models to make millions.
Open source AI can learn a lot from the history of open source. Whoever applies the lessons of the past and modifies them for the reality of ML will build a sustainable open source AI business.
They'll likely need to do two things very well:
Provide stock open source models but also provide custom fine tuned ones with robust safe guards
Deal with the complexity of serving and protecting the models at scale
Both of these strategies have roots in the successful open source businesses of the past.
There are essentially two open source strategies that worked to build billion dollar companies. The first was Red Hat's and the second was everyone else's since:
Red Hat's strategy was building a long lived, ten year support lifecycle for their OS
Everyone else, from Mongo to Confluent to Elastic, are basically SaaS shops that abstract away the complexity of running complex apps at scale
When it came to Linux, nobody could figure out how to monetize it, just like in open source AI now. A bunch of companies initially tried to build consulting services around the OS. The idea was that they'd maintain the OS and set it up and host it. That mostly didn't work. Some companies made some money, but they were basically just another IT shop that couldn't really deliver on the long term maintenance because long term maintenance is hard. It's a total grind over many, many years that no IT consulting shop could actually handle.
Red Hat delivered on the long term maintenance promise because they realized it needed a dedicated team of coders to fix bugs and security issues, not a consulting firm just dabbling in fixes when they felt like it or had the spare time. The long period of time was key too. They offered a 10 year maintenance cycle, which was essential back then, because enterprises had long live apps that they could not easily swap out just because the developers moved on to version 3 of some library and abandoned version 2 along the way. If you were a corporate customer that relied on version 2 you couldn't easily move to version 3 because your app might break. You needed someone who maintained that older version and got paid to do it.
At the time, open source developers were fantastic at coding those open source workhorses, but not great at long term maintenance. Too often developers completely dumped old versions in favor of new ones and that meant no support for production systems. Let's face it, maintenance is boring. Awesome programmers want to work on new code, not constantly backport fixes to old code unless it's their job.
We need something similar with open source models.
But maybe you're thinking that open source models don't have bugs?
They do. They just have different kinds of bugs.
The issues are new but they have roots in the past. People managed to jailbreak ChatGPT by threatening it and tricking it. That's really nothing but good old fashioned social engineering with a twist. Social engineering is when you trick a person into giving up personal information they shouldn't give up, like calling them up and pretending you're their bank and getting them to reveal their password because you're threatening to close their account.
Tricking ChatGPT is just tricking an AI instead of a person.
Not all the bugs are logic errors. They could be anything from undesired results to offensive results to dangerous results.
If I ask a diffusion model for a black man riding a bike in Uganda and it gives me a monkey on a bike instead that's incredibly offensive and needs to be fixed fast. If I deploy an open source chat bot to give psychological support to folks and it starts advising kids to commit suicide that's a massive and dangerous problem.
If someone is going to deploy these models in production for anything but niche use cases, they're going to need a dedicated team who can swoop in, fix models by training up a LoRA or a doing a fine tune of the model and getting it into the model inference pipeline fast. Imagine a team that could come in and quickly retrain the model to advise kids that they should look for help instead of taking their own life.
It's likely we'll see models with thousands of attached LoRAs or some alternative method to rapid-fine tune a model and then automated unit tests to make sure the model is behaving properly.
The models won't need a 10 year maintenance window because they're moving too fast and none of today's models will be state of the art in a year, much less 10 years but many will need still long term support of 3-5 years as the pace of innovation slows down.
Here’s exactly how not to support your customers in open source or otherwise:

AI companies will need to realize that their models are software and once they’re integrated into apps nobody can just transition off it in a week. This exactly parallels the early days of Linux.
Companies that have a throat to choke when things go wrong will feel a lot more confident in deploying AI into their software platforms. The teams supporting those models will need a combination of code, reinforcement learning and other "watcher" models to keep the original model in check. Those other models will either run as part of a pipeline, checking the outputs of the original model or in an ensemble configuration, where requests are fed to more than one model and the best output is checked and selected.
Think of it as intelligence maintenance.
Despite many people foolishly calling for us to come up with fixes and guardrails for AI before it’s very released, it’s just not going to happen. You can’t fix problems in isolation. You need to put them in the real world and expose them to real life to fix them.
These models are huge and open ended and that means there's simply no way to automatically test everything that could possibly go wrong. If I can ask a chat bot anything, there is simply no way to test everything that anyone could ask it. That's a different attack surface than traditional programs. If I write a login script, the code generally does one thing and it can only go wrong in so many ways. But with a LLM that you can ask any question, in any way, it's too much to test ahead of time.
AI maintenance will have to address everything from attacks on the model's logic, to weird edge case errors, to model hallucinations, to bad mistakes, to undesired outputs, and alignment issues.
Nobody wants a chat bot that tells kids to kill themselves, or suggests two drugs that have bad interactions, or goes on a Nazi rant. When that happens those companies using the models in their apps will need a throat to choke. They'll need a company or project that can rapidly fix that with another model in the chain, coded safeguards, fine tuning or reinforcement learning.
In other words, they'll want and need someone to blame and most importantly, someone to fix it.
That brings us to second major business model in open source.
Everyone who came after Red Hat needed a different business model. That's because software was changing. Companies used to have a lot of long lived apps that were developed in house and maintained for a decade or more. Some of that still exists for sure but more and more companies started iterating and updating faster. We saw a merger of the speed of consumer apps with enterprise software. Companies swapped out old in-house dinosaurs for SaaS platforms with interfaces as good as consumer apps but able to do complex enterprise tasks.
The open source companies that hit billion dollar unicorn status, like MongoDB, Confluent, Elastic, after Red Hat tended to follow a different model:
Managing complexity and scale.
Take something like MongoDB. It's easy to get started with MongoDB because it's open source and you don't need permission to set it up and use it. But as soon as you started to try to scale it in production it became a bit of a nightmare. MongoDB's parent company abstracts away that complexity.
Open source AI will need to do the same. It will take those big, complex workflows we talked about earlier and find a way to deploy them and manage them for customers at scale.
But no matter what happens, building a business with open source is very different from building a closed source business. A company needs to know where they stand and then focus on that from the very beginning. It won't be easy to change later on down the line.
I'm worried that many open source AI companies are not getting the business aspect right and they'll be out of business and we'll be left with totally closed source models like GPT-4 where we don't know the first thing about how it was trained, how big it is, what it's architecture is and why it works at all.
The world is better when it's open but with a retreat of globalization, a massive push by artists to expand copyright out of fear (and who don’t yet seem to realize that they’ll find themselves calling up Nintendo to beg permission to paint Bowser as a result), and the massive fear mongering around AI in general aka “the robots are coming for all our jobs” (they’re not, really they’re not), as well as a desire for companies and countries to control the future of AI, we may be in for a big battle and a return to an era of secrets and proprietary code for a time.
In the end, on a long enough time line, open tends to win out, but that doesn't mean that we can't have an era of closed before it happens.
Flying At the Speed of Light
But no matter what, right now is one of the most exciting times for AI. It's flying at the speed of light.
Usually at the start of any tech revolution you get breathless articles about how fast everything is moving. That’s mostly an illusion. At one point it felt like every article coming out of Wired for the first decade of the Internet was about how fast it was moving but when you really look back at it all, it wasn't moving as quickly as we felt or remember.
I got my hands on the first iPhone in 2007 and imagined a world of ubiquitous apps and total connectivity happening in an instant. In actuality, it sold 6 million units. What I ended up with as a phone with a web browser, pdf reader and a calculator and slow download speeds. It wasn't until 5 years later and that they managed to break 100m units sold. It took two years before WhatsApp launched in 2009 and another two years before it hit 100 million users.
But this time it is moving very fast.
It took only two months for ChatGPT to reach 100m users.
AI feels different. It's intuitive. Natural. We seem to understand it right out of the box. We know how to talk to something and ask for what we want because we've been training our whole life for it. It's getting adopted at an astonishing pace.
Charles Frye, a deep learning teacher, said that after a decade in neural nets he felt like a dog that finally “caught up with the car it was chasing, sunk its teeth in the fender, and is now traveling at 80 mph -- tail wagging, jaw tiring.”

I understand why it feels terrifying to some people, even many folks who were there for the early days of the net and surfing the wave rather than resisting it. We've also got decades of scary sci-fi stories about AI taking over the world and escaping its cage. If you want to get a lot of retweets just write about AI taking over, destroying all the jobs or "escaping" and going crazy. You're virtually guaranteed a few million retweets because it's emotional and cuts to the very heart of our fears and desires.
But AI is not like sci-fi in the movies. It's not escaping. It doesn't have any of its own desires. It's not sentient. Really, it's not.
It's not going to destroy all the jobs. I repeat, it's not going to destroy all the jobs. It will replace some but not overnight and it will change others but that's all right. We've already destroyed all the jobs multiple times in history and we've always created new and more varied jobs.
At one point everyone's job was hunter-gatherer and then 90% of us worked on farms. Today 3% of us work in agriculture and the rest of us are artists, doctors, lawyers, DJs, construction workers, booksellers, programmers, chefs and a million other kinds of jobs that didn't exist even a few hundred years ago and sometimes even twenty years ago. At one point the electric light knocked out the whale oil candle industry but nobody is clamoring for a return to hunting sperm whales so we can dig white gunk out of their heads to make candles.
That said, AI will change the nature of work. AI won't replace the radiologist but a radiologist working with AI will replace the one who refuses to use AI.
AI will build new tech behemoths, and radically change many industries. But to build those defensible AI businesses, companies will need to create amazing new interfaces that we've never seen before and they'll need patience, money, time and luck. They'll have to learn the lessons of the past and adapt them to needs of today.
For all of us who are a part of this or seeing it develop, it's like watching a tsunami swelling far out to sea.
The best advice I can give anyone is get your surfboard ready.
And make sure you surf that wave rather than get crushed by it.
