Why Foundational Models will Revolutionize the Future of Work and Play
The Age of Ambient AI, Anchored by Mega-Models in the Cloud, will Supercharge the Future of Work and Play and It's Coming Much Faster than Anyone Realizes

(Source: Imagen - Google Research)
It's 2033 and you're coming home from a dinner and realize your sister's birthday is tomorrow and you forgot.
You ask your phone what's the best gift for her and where you can get it at this late hour?
Your phone has dedicated processors for running Machine Learning (ML) models locally but it's not powerful enough to answer that question with its small memory and slower chip speed. But it is strong enough to ask a more powerful model in the sky.
The local model also learned a lot about what you and your family likes over time, so it packages up some key things it knows, anonymizes them, and fires off a query to a Foundational Model (FM) in the cloud via API.
In a fraction of a second, the answer comes back.
Your sister's latest social media pics show she recently got on a serious health kick, lost weight, stopped drinking and got really into vegetarian cooking so it recommends an AirBnB cooking experience near her, with a local vegetarian chef. It gives you two alternative experiences that are good but a bit further away and not as highly rated. You don't even need to go to the store and it's the perfect present that makes you look like a hero.
Later on you're worried about a spot on your arm and you take a quick picture of it. The medical image recognition model on the phone thinks it's worrying and you go suddenly cold.
What if I have cancer? What do I do? Who do I call?
But the app wants to double check with a medical multi-modal foundation model in the cloud that's continually training on newer and better images from around the world and pulling in lots of other information to cross check. The app asks your permission to have it looked at by the medical model in the sky and you say okay. You hold your breath, your heart thundering and your mind swirling with questions.
A few seconds later it comes back and you breathe a sigh of relief.
It's not dangerous but the app recommends you have a deeper scan from a local doctor anyway just to be safe and to put your mind at ease.
It also recommends you put on sunscreen every day.
But that’s just a beginning of how FMs have achanged society and work and play.
Across the world people are using cascaded FM's networked together to do amazing work. FMs on their own are amazing but working together they're capable of astonishing feats and when they work with you they're centaur units, a combination of man and machine working together to create something neither could do on their own.
Centaurs are named after Gary Kasparov’s early experiments with chess tournaments, where an AI and human teams bested pure AI and humans on their own. The tournament’s name came from the mythical beast of Greek legend that’s half horse and half man, symbolizing how man and machine can work together better.
Gmail back in 2022 already suggested ways to complete sentences and it worked surprisingly smoothly, finishing sentences like “It was nice to meet you the other day” or “let’s find a time that works for everyone.” Now in 2033, email and chat platforms compose whole texts, emails, documents and slide decks to save time for billions across the world. It even generates the stock imagery in those decks from scratch.
That's just the tip of the iceberg though. Centaurs and Foundational Models have surged into every aspect of our lives.
Designers and animators are using them to generate thousands of potential concepts for new movies and video games they’re creating. Animators at Pixar and Marvel and Disney work with Foundational Models as a Service (FMaaS) companies to fine tune the model on their private datasets of brilliant concept art and suddenly find the model helped their animators go in a totally different direction. That leads to their next movie topping the charts as the all time highest grossing film in history, only to top it again three years later with another man-machine hybrid.
Biotech companies search through massive databases of proteins and chemical interactions and quickly use a fine tuned FM to design twenty potential drug candidates to fight a rare motor neuron disease that recently cropped up in South Africa.
A musician jams out a new tune and then asks the models to iterate on the chorus. The 17th one is awesome and the musician plays it and then modifies it with a few tweaks to make it even more catchy based on a song he couldn't get out of his head a week ago that he overheard on a radio at the local park. It goes on to be a huge hit on Soundcloud.
Materials scientists are designing new materials that make everything stronger and lighter, from skyscrapers that flex more easily to resist earthquakes, to electric bikes that are light enough to carry on your shoulder and fold up neatly to carry on the train.
Elite coders are simply telling the coding model what they want it to do and its spitting out near perfect Python code but it also recommends Go for several libraries because it will be faster and more secure. It automatically does the translation between languages and tests it. It's paired with an evolution through language model (ELM) coupled with a Large Language Model (LLM) and those models helps the coder create brand new, never before thought of code too, in a domain the model was never trained for by iterating on concepts quickly.
All of it is happening because of a vast global network of ambient AI models. AI is everywhere now. Every device is waking up and getting smarter. We've industrialized intelligence and sparked a revolution in how we work, design, and play.
Welcome to the age of ambient AI.
Industrialized intelligence has surged into every aspect of life from the arts, to the sciences, to defense, to programming and more. FMaaS now infuses software everywhere across the world.
The compact edge AIs running on neural chips in your phone and watch and glasses act as a universal interface to the deeply intelligent, multi-modal and multi-functional models in the sky.
Now let's roll back to today and find out why and how it all started.
The Foundation of the Tomorrow
What are Foundation Models and why do they matter?
In essence, FMs are large models that exhibit remarkable capabilities, such as the ability to understand language, reason, create working computer code, do translations and arithmetic, understand chains of logic, generate totally new art from text prompts, and much much more.
The basic concept of FMs comes to us from Stanford University where they primarily refer to Large Language Models (LLM), like GPT-3, that are typically transformers. But the implications of FM's go way beyond today's architectures. They're a groundbreaking type of software, that's not limited to transformers or language.
We can think of FM's are any large and sophisticated model. We can also think of them as a chain of cascading models that work together to do a complex task such as generate music or images or video, create mathematical proofs, design new materials or discover new drugs and more.
Many of them are already here.
GPT-3, from OpenAI, powers GitHub co-pilot that quickly writes code for developers, especially boring, repetitive code so they can focus on more creative tasks. It's one of the first fantastic examples of a centaur. Originally, GitHub's team wasn't sure who would use it. Would it be beginning or advanced coders? Since its wider release to all developers, the answer is clear: advanced coders love it and use it most often. Advanced coders are in the best position to understand when the model makes a mistake and it dramatically speeds up their day to day coding.
In a blog review, one programmer working with it wrote: "I have tried it for five months now and I am amazed."
Saumya Majumder, a Founder & Chief Web Engineer at @AcnamHQ had this to say:
"I am truly amazed by the potential and craziness of #GitHubCopilot. I mean, it seriously is crazy. Initially, I was very skeptical about how good it will be or will it help me or not. But now, it literally completes my thoughts as I am thinking them. Like it can read my mind."
But if foundational models by themselves are amazing, what happens when you link them together?
That's already happening right now too. Researchers have already discovered that if you put these models together like Lego bricks you can do some amazing things.
Take DALLE-2, the generative art bot that's taking the internet by storm (and that OpenAI still hasn’t given me access to, come on guys!) The team trained up a LLM called CLIP to understand how to interpret what people were asking for and then a diffusion model to generate the images. It generates beautiful art from nothing but a text prompt and boasts the ability to "in-paint" or change sections of the picture with more prompts.

(Source: DALLE-2 and David Schnurr)

(Source: DALLE-2 Bot, Homer Simpson in the Sopranos)
Google took the idea of DALLE-2 a step further with Imagen. Instead of training a new LLM, they just took one called T5-XXL that already had a deeper understanding of language and paired that with their own diffusion model that created an unprecedented level of photorealism.

(Source: Imagen - Google Research)
Using an existing model also gave Imagen some impressive new skills, like being able to spell words correctly, unlike DALLE-2 which can’t spell if its life depended on it.

(Source: Imagen - Google Research)
More researchers will inevitably take this cascading model strategy farther and farther. It's already happening and it will only accelerate.
Research just coming out of OpenAI paired a LLM with an evolutionary algorithm and got it to generate thousands of working Python programs that made little 2D ambulatory robots walk. Usually evolutionary algorithms work with entirely random permutations as they evolve. But paired with LLMs the researchers found they could speed up evolution because the LLM could understand logic and reasoning and make educated guesses on the next permutation, much the same way humans reason in a new situation. We don't start from scratch but from a foundation of previous knowledge. This has tremendous implications for open-ended learning in the next generation of models.
People are also working towards more universal architectures they can throw at any kind of problem. Google just trained up a brand new architecture that they hope can learn any kind of task, called Pathways. They explain the concept perfectly on their blog:
"Today's AI models are typically trained to do only one thing. Pathways will enable us to train a single model to do thousands or millions of things."
That will move us beyond narrow AI into AI that can handle a broad range of challenges.
They even built a brand new AI infrastructure system to scale training more efficiently based on JAX, their likely replacement for Tensorflow and answer to Pytorch from Facebook.
The first Pathways model they trained, PaLM (Pathways Language Model), is 540B parameters and exhibits breakthrough capabilities in multiple categories. Their model gets more and more capabilities as it grows, developing the ability to translate, do math, summarize text, answer questions, reason, write code, and more, all without having trained specifically to do that task.
Their website says that "PaLM 540B shows strong performance across coding tasks and natural language tasks in a single model, even though it has only 5% code in the pre-training dataset. Its few-shot performance is especially remarkable because it is on par with the fine-tuned Codex 12B while using 50 times less Python code for training. This result reinforces earlier findings that larger models can be more sample efficient than smaller models because they transfer learning from both other programming languages and natural language data more effectively."

(Source: Pathways website)
It can even explain jokes.
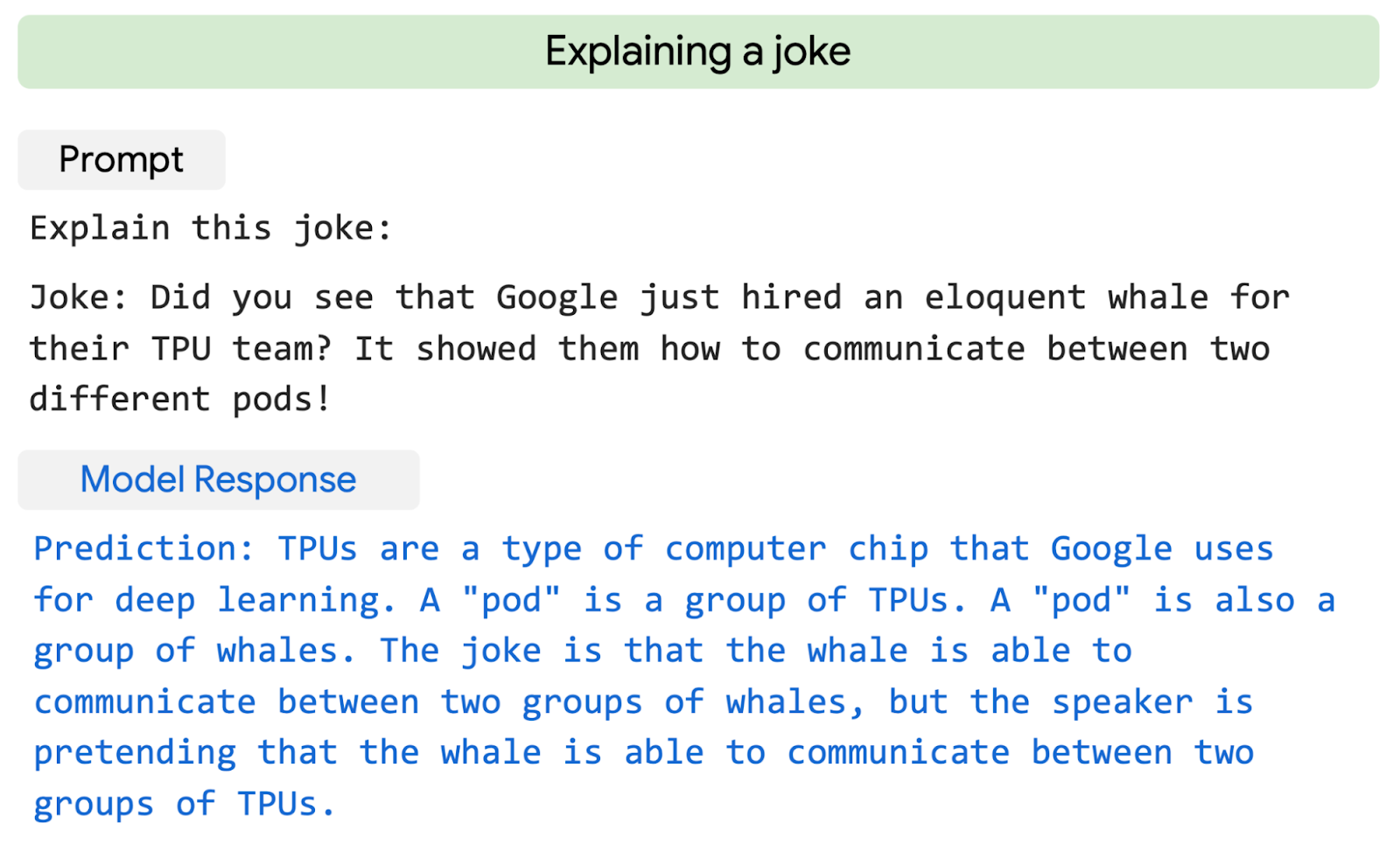
(Source: Pathways website)
Today we have 500B parameters models and reports out of various research facilities show we already have 1 trillion parameter models. Researchers will continue to push the state of the art forward. In a few years we'll have 10-20 trillion parameter models and even 100 to 500 trillion parameter models that are commonplace.
As the Economist writes in a recent article on Foundational Models:
"One of the remarkable things about this incredible growth is that, until it started, there was a widespread belief that adding parameters to models was reaching a point of diminishing returns. Experience with models like Bert showed that the reverse was true. As you make such models larger by feeding them more data and increasing the number of parameters they become better and better. 'It was flabbergasting,' says Oren Etzioni, who runs the Allen Institute for ai, a research outfit."
It seems we've only scratched the surface on what larger models can do.
A research team out of China already trained a 500 trillion parameter model called BaGuaLu, 5X the size of the human brain.
The human brain can theoretically handle 100 trillion parameters.
The researchers are notably silent on most of its capabilties, likely because it has defense implications but the merge of supercomputing and mega-models will only grow faster in the coming years.
Graphcore, a UK chipmaker, is working to build and ship a megachip that they hope will power 500 trillion parameter models on a single chip or set of tightly coupled chips and they want to do it at scale.
Maija Palmer writes, in an article for Sifted, "Graphcore’s computer would be ready to ship in two years and cost just $120m, the kind of price that makes it accessible for individual companies and universities. For context, $120m is a fraction of the $1bn it cost to build the world’s fastest supercomputer, Japan’s Fugaku.
“'This is not a one-off. It is a product we intend to deliver in volume because it is what our customers have been asking for,' says Simon Knowles, cofounder and CTO at Graphcore."
In another article, called The Coming Age of Generalized AI, I highlighted researchers who were working on even more groundbreaking approaches by combining mega-models with several other key techniques. One of techniques, called progress and compress that comes to us from DeepMind, combines three techniques, progressive neural networks, elastic weight consolidation and knowledge distillation.
The idea is simple. Create two networks, a fast learning network and a base model. That roughly mirrors the functioning of our brain yet again. Think of it as the hippocampus and neocortex. As Hannah Peterson writes in her article on catastrophic forgetting, “In our brains, the hippocampus is responsible for “rapid learning and acquiring new experiences” and the neocortex is tasked with “capturing common knowledge of all observed tasks.” That dual network approach is called a progressive neural network.
The fast neural network is smaller and more agile. It learns new tasks then transfers the finalized weights to the base model. So you end up with a lot of stored neural networks good at a bunch of tasks.
But there’s a problem with basic progressive neural nets. They don’t share information bi-directionally. You train the fast network on one task and freeze those weights and transfer them to the bigger network for storage but if you train the network first on recognizing dogs, it can’t help the new network training on cats. The cat training starts from scratch.
Progress and Compress fixes that problem by using a technique called knowledge distillation, developed by deep learning godfather Geoffrey Hinton. Basically, it involves averaging all the weights of different neural nets together to create a single neural network. Now you can combine your dog trained model and cat trained model and each model shares knowledge bi-directionally. The new network is sometimes slightly worse or slightly better at recognizing either animal but it can do both.
It opens the door to cat-like intelligence.
A cat is a remarkable creature. It can run fast, sleep in tiny boxes, find food and water, eat, sleep, purr, defend itself, climb trees, land on its feet from great heights and a hundreds of other subtasks. A cat won’t learn language or suddenly start composing poetry. That’s perfectly fine because a cat is really well suited to its set of tasks; it doesn’t need to build skyscrapers too.
Having a cat level intelligence is incredibly compelling. If you have a cleaning robot that can wash dishes, pick up clothes, fold them, carry them from place to place and iron shirts, that’s an incredible machine that people would clamor to buy. It doesn’t also need to write music, craft building blueprints, talk to you about your relationship problems, and fly a plane too.
As Raia Hadsell, head of robotics at DeepMind, says in this excellent article on How DeepMind is Reinventing the Robot:
“I find that level of animal intelligence, which involves incredible agility in the world, fusing different sensory modalities, really appealing. You know the cat is never going to learn language, and I’m okay with that.”
Today's Foundational Models will undoubtedly change as researchers combine more techniques and figure out better and more efficient ways to train and teach models.
OpenAI already discovered that today's large models are probably dramatically undertrained and too big. They recommend scaling up the data and training a smaller model for longer, which makes it more compact and faster on inference. They trained up Chinchilla, a model with 70 billion parameters, that performed as well or better versus mega-models like Megatron Turing (MT-NLG) that has 500B parameters.
But of course, there is more than one way to skin a cat. Google's PaLM has 540B parameters and remains state of the art.
So maybe the truth is we need bigger models that are trained longer too?
Or maybe we need more networked models with intelligent routing to specialized networks that know exactly how to solve a problem? A neural net with advanced reasoning could figure out how to route requests to more specialized nets to get the best answer in a wider variety of situations.
Even more approaches are inbound. Geoffery Hinton outlined a radically different approach on a podcast with famed robotics researcher Pieter Abbeel:
He said we'll have to move beyond backpropagation to get to what the human brain can do. Neural nets now function the opposite of how the brain works today. They form a compact representation on a smaller subset of neurons from a lot of data. But in the human brain neurons are cheap and so the brain learns from very little data but spaces the representation and reasoning out over a wider range of connections.
Compute will play a big part in the models we build tomorrow as well.
We've already seen approaches like Graphcore's and rival chipmaker’s Cerberus, that also makes massive chips on a single die.
Integrated photopic chip research, using light instead of electricity, will deliver chips 10,000X more efficient and much faster too, a breakthrough that will mirror the jump from vacuum tubes to transistors at Bell Labs, also a 10,000X improvement. That improvement ushered in the modern, networked world of global communication. The next one will usher in the era of ambient intelligence.
But even without those kinds of hardware breakthroughs, companies like NVIDIA continue to pump out incredible new chips that when networked together deliver incredible performance, like today's A100 TensorCore. Faster chips are coming this year and next, the new NVIDIA chips named after the enchantress of numbers, Ada Lovelace, a woman dramatically ahead of her time too.
Along the way, we'll need newer interconnects and ways of dealing with this massive growth. The BaGuaLu team already highlighted the weakness of interconnects in modern supercomputers in their paper:
"The work on MoDa has exposed the inefficiency of the current state of the interconnection of HPC systems for the latest pretrained models. Although the oversubscribed network topology reduced the effort required to build a large-scale system and is a good fit for many traditional HPC applications, MoE requires massive All-to-All communications that break the optimal process mapping for neighbor communication. New advanced interconnect techniques are needed to address AI training workloads. We expect that our exploration of the communication patterns of training models at such a scale can benefit future studies in both AI and HPC."
Infrastructure software will make a big difference too. We'll need a robust stack to ingest, clean, train, experiment, serve, monitor and manage all these AIs.
That's why we founded the AI Infrastructure Alliance. We're bringing together all the best and most cutting edge AI infrastructure software makers to get them working together and building the canonical stack that will let anyone train and fine tune models. It's likely that stack will need to advance beyond what we already have now to power next gen AIs and their cutting edge architectures. It’s also why Google built Pathways to deal with scheduling and interconnect problems, and it's why the UC Berkeley RISELab team build Ray. It was designed primarily as a tool for Reinforcement Learning (RL) and as a "replacement for Spark," with a specific ML focus, since many kinds of ML jobs do not fit into MapReduce style paradigms. As Computer Science professor Michael Jordon wrote in an article from 2017, in the early days of the project:
“You need flexibility. You need to…put together not just things like neural nets but planning and search and simulation,” Jordan said. “This creates all kinds of complex task dependencies. It’s not very easy simply to write a MapReduce kind of paradigm. You can write it but it’s not going to execute very effectively when you have very heterogeneous workloads and tasks. It needs to be adapted to the performance of the algorithms, as the system is learning, to change its flow, its tasks.”
The platform has since adapted to being a more general purpose compute framework for machine learning through Dataset, a distributed data loading and compute library, though it is still most often used for reinforcement learning and as a serving engine.
We will likely need more low-level frameworks to and hardware interconnect solutions to match to really get the all-to-all communication optimized.
Either way, we can expect a whole array of approaches that help us build more ultra-intelligent machines. New compute. New interconnects. New infrastructure software. New neural designs.
Expect more architectures, new approaches, more networked models, bigger models, longer training, and more powerful intelligence as researchers dig deeper and deeper and unlock more of the mysteries of the human brain and the artificial mind.
What will it all mean?
In case it’s not obvious by now, all of this has incredible implications for the future of work and play.
To understand why you just need to understand a little about why universal technologies presage a massive uptick in human societal complexity.
Industrialized Intelligence and the Future of the World
AI is a universal, general purpose technology.
The greatest breakthroughs in history are always universal technologies that affect a broad range of sectors as they branch into countless other domains and inspire unexpected breakthroughs.
Think of the printing press and the way it leveled up human knowledge across the board because now we could scale, save and replicate knowledge much faster.
Think steam engines that changed the very nature of work from human and animal powered muscle work to work done by machines.
Think of the microprocessors and computers that changed how we do art, communicate, design skyscrapers and houses, fight wars, find love, do science, make music and movies and more.
A general purpose technology like AI has direct and secondary effects on the world at large, both good and bad and everything in between.
We can think of ideas and technology as they grow and change and affect both their own domains and unexpected domains as a growing tree. The roots are precursor ideas that eventually inspire the primary idea. The trunk is the central breakthrough idea, which leads to a branching series of closely related ideas and some unexpected inventions in parallel domains.
I call it the Branching Tree Effect.

More recently, Google used the branching tree to showcase how large Machine Learning (ML) language models, like their Pathways ML model, develop emergent behavior in multiple domains like reasoning and translation and writing code as it grows larger over time.
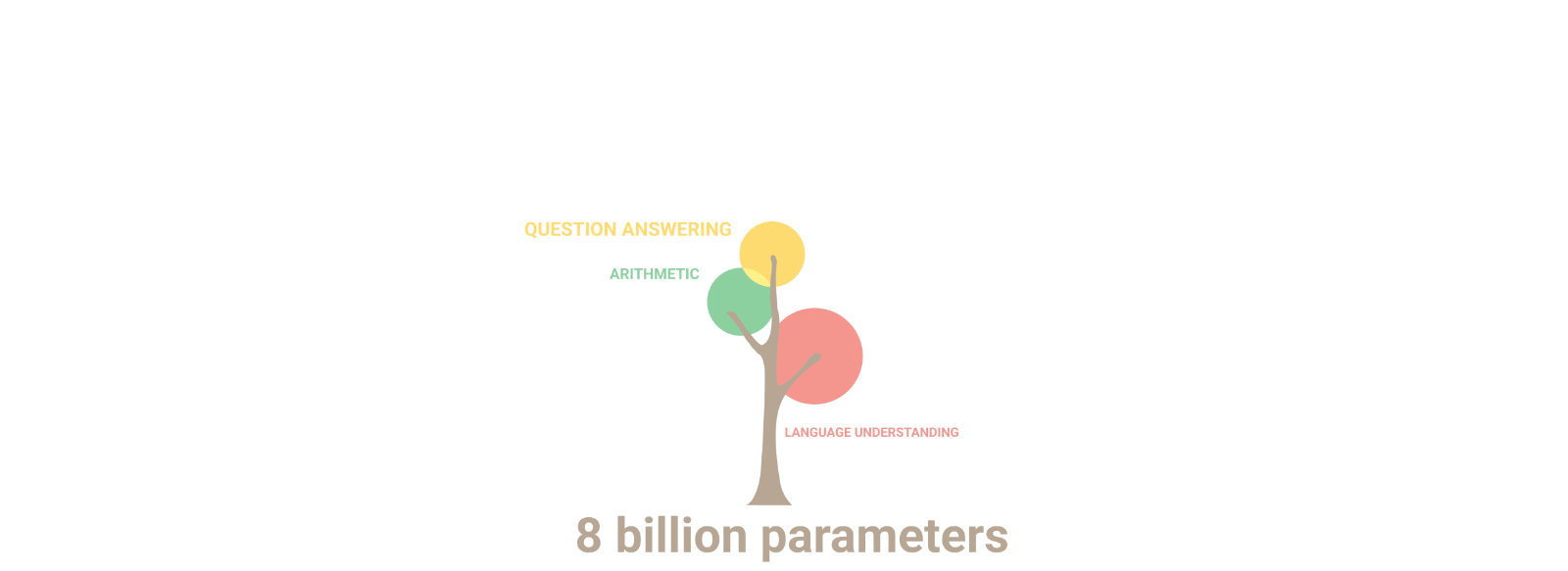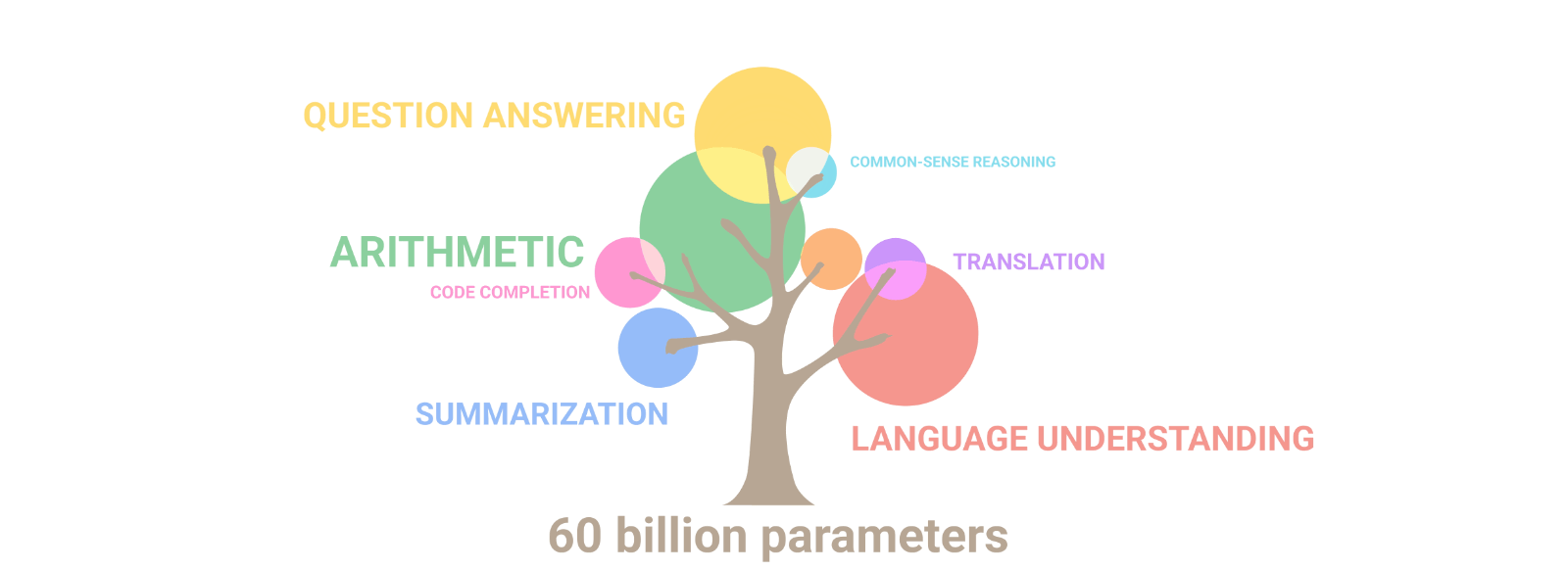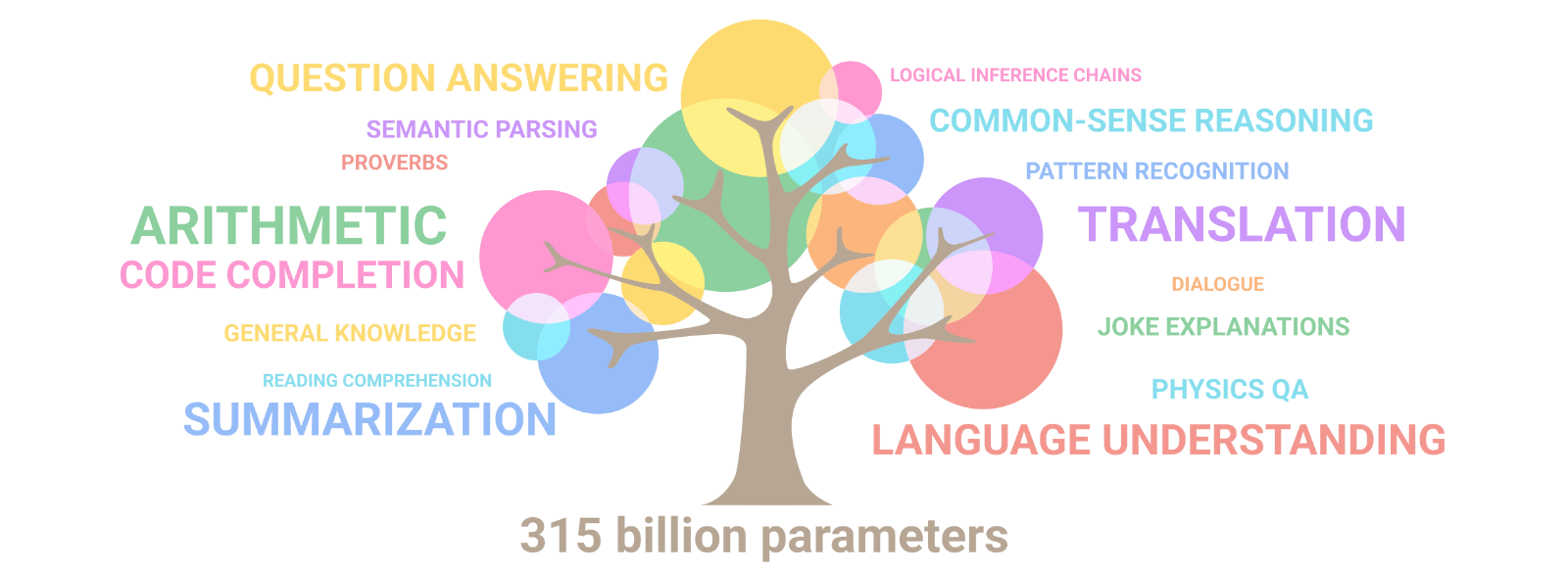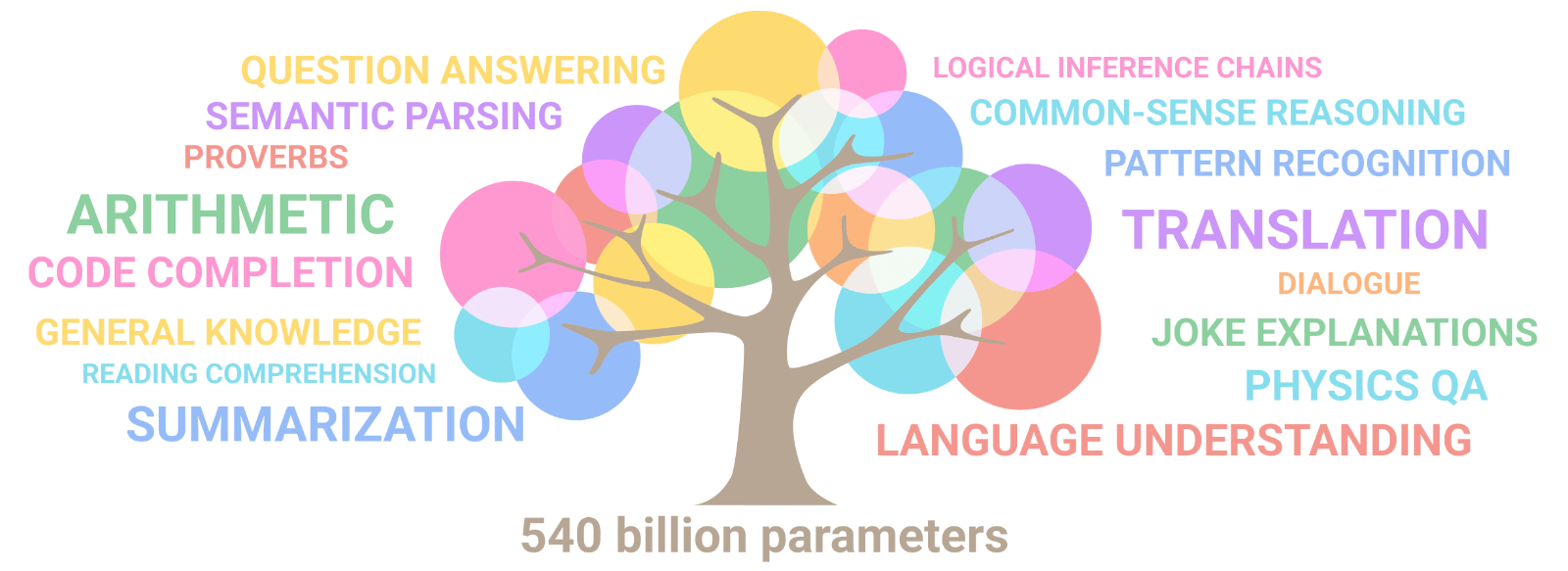
(Source: Google blog, Pathways ML model description)
The Branching Tree is a foundational metaphor for ideas and technology and for all knowledge and inventions as they ripple out into society and spread.
And few technologies today will spread as far and as wide as AI. There is literally no industry on Earth that won't benefit from getting more intelligent.
Imagine a whole network of these models working on problems as diverse as logistics, defense, materials science, biotech, finance and art. These models are the key to leveling up the intelligence of hundreds of industries.
Many companies will use AI directly. They’ll create smaller models and edge models and specialized models for their organizations. But FMaaS are the cornerstone of tomorrow. Those edge AIs will communicate back to the FMaaS.
Why run them as a service?
Because these models are very expensive to train and to serve. Inference alone can use whole farms of GPUs and tensor cores and cost 10s of millions of dollars. FMs will require supercomputers and GPUs/TPUs at scale, not to mention advanced software and a highly skilled labor force to deploy, monitor, update and manage them. These resources are out of the range of most companies today, even large enterprises so we'll likely access them in the cloud and eventually on the distributed compute of a decentralized net too.
Whether we can make these models smaller and more compact to run on more distributed devices is an open question that only time can answer. But for now, bigger is better and the cloud is king.
And in the near term one thing is abundantly clear:
FM's are the foundation of the future.
They will power software, work and play.
And along the way they will change life in ways we’re only beginning to imagine now.