AI’s Phoenix Project Moment
In the late Arizona evening of 2018, on a desolate stretch of two lane highway, Elaine Herzberg earned a distinction she never wanted.


In the late Arizona evening of 2018, on a desolate stretch of two-lane highway, Elaine Herzberg earned a distinction she never wanted.
She became the very first pedestrian ever killed by a self-driving car.

She shared a similarly sad fate to a woman 122 years earlier, Bridget Driscoll, who died in 1896 while walking in the late London day at the hands of an earlier experimental technology:
A car.
The general public likes to think of AIs as superhuman and in a way they are superhuman. They can beat the best players in the world of Go or 99% of the players in the world at DOTA 2, a real time strategy game of amazing complexity.
But that doesn’t make them perfect. Even the most advanced AIs today make bad mistakes, including mistakes that most people would find trivially easy to overcome.
When we take AIs of out of the narrow realms of board games and video games and put them into the real world, they face a never-ending list of edge cases and unexpected scenarios. Nowhere is that more apparent than in the high stakes world of autonomous cars where every mistake could mean the difference between life and death.
The list of things that can go wrong for an autonomous vehicle “is almost infinite,” says Luc Vincent, who heads R&D for Lyft’s self-driving car unit.
Lyft found that its cars were slamming on the breaks when they got cut off by other drivers. Another autonomous car company, Zoox, found their cars couldn’t deal with yellow left hand turn signals, because most turn signals are green. They had to bring in artists to paint yellow turn signals to load into their simulation software. Soon Zoox’s cars got a lot better at seeing them in the real world but no matter what you do there is always another edge case.
“It’s a bit like a whack-a-mole. You solve one problem, another might emerge,” said Applied Intuition CEO Qasar Younis, according to CNN’s excellent article on the endless difficulties faced by this “generational type technical challenge.”
Famed roboticist and professor emeritus at MIT, Rodney Brooks, wrote a wonderfully long and detailed post on why he thinks self-driving cars are a lot further away than almost anyone thinks. He lays out dozens of edge cases:
If you went down a narrow one way street that was blocked off by construction is it okay to break the law and back down the one way street?
Could the car handle teenagers pranking and yelling conflicting commands?
Can the car understand hand signals from police or road-side workers?
Can the car recognize a fake street sign that someone put up or a damaged one?
Becoming Duck Aware or the Limits of Machine Reasoning
All of these scenarios are immensely difficult for today’s AIs because they have no deeper contextual awareness or general purpose abstract reasoning. Contextual AI is the bleeding edge of AI research, which is why it’s got funding from futurist organizations like DARPA.
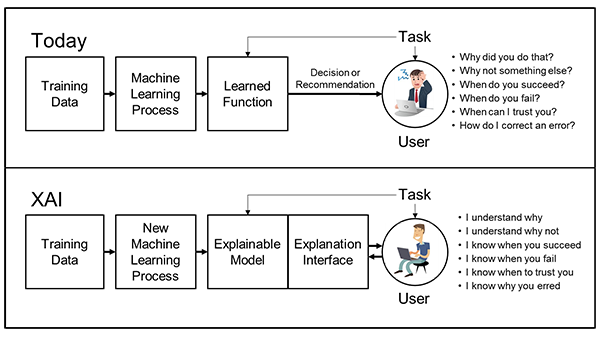
What makes humans so amazing is how adept we are at abstracting solutions from other problems to brand new problems we’ve never seen. We can study the laws of physics and motion and inertia and build a rocket that’s never existed before and land it on the moon the very first time.
A convolutional neural net (CNN) can study examples of a rockets but if there are no ready made solutions to building a rocket then it can’t invent one. A CNN that’s never seen a duck won’t suddenly become duck aware.
Self-driving cars push the limits of what’s possible. Wildly optimistic predictions that we’d have autonomous vehicles confidently navigating the mean streets of New York City by now are giving way to the reality-check realization that it may take a lot longer than we thought.
At one level, we’re coming up against the limitations of what deep learning and reinforcement learning can do. At the latest NeurIps, one of AI’s biggest conferences, some of the industry’s brightest stars, including Yoshua Bengio, director of Mila, an AI institute in Montreal, gave a sobering message about the state of AI today:
“We have machines that learn in a very narrow way,” said Bengio. “They need much more data to learn a task than human examples of intelligence, and they still make stupid mistakes.”
Roboticist Rodney goes even further, saying that to have a true level 4 or level 5 self driving car, meaning cars that don’t need a wheel and can drive in anything but the worst weather conditions and make their own decisions, will require something approaching Artificial General Intelligence (AGI). It’s not enough to stitch together a bunch of disconnected neural nets and hope a higher form of understanding will magically appear.
To make an autonomous car work in the chaos of the real world, with drivers honking and cutting you off, gaping potholes, broken traffic lights or street signs covered in stickers, there’s a very real chance that we just can’t get there with the start of the art in AI today. Whether we can make self-driving cars work with the magic of neural nets now or if we need new kinds of algorithms will get decided in labs of the planet’s top R&D teams as they race to find solutions.
But if we look closely, the world of self-driving cars show us an even more basic and fundamental problem that’s destroying data science teams and it’s one we can fix right now.
Red Teams the Rising Phoenix
There’s a reason that 87% of data science projects never make it to production.
Most data science teams today have no idea how to deal with edge cases that multiple like wild rabbits as our models come up against real life.

Algorithms that learn for themselves have all kinds of scenarios we just can’t see coming until they hit us right in the face. If your visual detection system has a 97% accuracy but detects a graffiti covered stop sign as a 45 MPH sign it might as well have an accuracy of zero because someone will get hurt or killed.
Even the most accurate and successful CNNs in the world often struggle in the messy real world. MIT and IBM just put out the ObjectNet dataset to show just how badly these algorithms can perform when faced with damaged things, or partially hidden things, or things sitting at strange angles. The dataset took three years to put together and some of the most advanced object-detection models saw their accuracy rates plunge from 97% on ImageNet to just 50–55% on ObjectNet.

It’s just not enough to test accuracy and call it a day anymore. Accuracy scores mark the bare minimum of competence for a model. Those scores are like the two people you put on your resume to vouch for you in a new job. They signal you’re not so incompetent that you can’t find two people in the whole world to say nice things about you and that’s about it.
But to make something as complex as self-driving cars a reality we need a way to solve the problem of rapidly proliferating edge case whack-a-mole. To do that we need to go beyond overall accuracy and move to automated testing of accuracy on edge cases. And we can do that by turning to traditional software programming.
AI development has its own unique challenges but there’s a lot of overlap between how we develop software on some of the most elite programming teams and how data science teams will develop AI now and in the future.
To understand why you only need to know a tiny bit about the history of programming.
DevOps was the answer to a big problem that only came to light as our applications started to get too big and complex for old programming methodologies to handle adeptly. Early computer applications were simpler than today’s multifaceted apps. They primarily got built by corporate dev teams for a narrow use case. With those apps hidden behind corporate firewalls the waterfall model worked beautifully. Only a few thousand users would ever touch that application so you could keep the edge cases to a minimum.
But the Internet changed everything. With 100s of millions of users using an app, more and more bugs pop up versus just a few thousand users in a strictly controlled environment. DevOps came to the rescue. It made Internet scale applications possible.
AI changes the game again.
With AI we’re facing an exponential rise in unknown unknowns.
The key to fixing it is a unit test.
We can think of every edge case as a bug that needs an automated unit test.
The rise of Agile and DevOps style programming taught us how to automate tests as complex software goes through countless changes at the hands of a widely distributed programming team. Software teams often find that a networking bug that got squashed somehow came back a hundred revisions later because a programmer checked in code that’s dependent on a broken library or because the programmer cut and pasted old code without realizing it had flaws. AI teams will need to develop their own automated edge cases processors for dealing with fraud detection systems that start getting false positives every time someone travels to France or uses an ATM in Albuquerque.
When we tweak the parameters of an algorithm or retrain on it new data and it suddenly starts making mistakes, AI teams will have to build special tests to make sure those “bugs” don’t come back out of the blue. A self-driving car team might create a CNN that’s masterful at dealing with angry human drivers cutting them off but if it suddenly starts missing street signs with stickers on them again it doesn’t much matter.
To build a better unit test engineering teams will need to master Machine Learning Operations (MLOps) and learn to build a well oiled MLOps pipeline that can find and squash new bugs fast.
In my talk for Red Hat OpenShift Commons, I talked about how to build a QA for AI team which I’m now calling the AI Red Team. This is a team of rapid-responder coders, engineers and data scientists who find short-term triage solutions and long term solutions to AI anomalies. This is a highly elite team, much like a white hat hacker squad, whose job it is to break into networks to make them safer from black hats.
The AI Red Team’s job is the answer to Murphy’s Law. They specialize in breaking AI and fixing it again. They’re in charge of ferreting out the unknown unknowns and bringing them into the light before they hurt someone or hurt the bottom line.
In the not too distant future, we’ll need millions of Red Teams across the world building their own ObjectNets and sharing them in the true spirit of open source to really create cars that can back down a one-way street safely or make their way through slashing rain and snow.
Think of this as The Phoenix Project for AI.

If you don’t know the book, you should. It’s a ripping good read on software and business transformation. Any book that can make software development and business process upgrades into a fun and super entertaining ride filled with characters we all seem to know in the real world is something special indeed. The book helped popularize the DevOps software development model but more than that it showed how we can solve problems of the past by thinking differently about them at every level of an organization.
We’ll have to transform our understanding and our methods once more in the age of AI.
AI brings new challenges that we’ve never faced when we coded all software manually and taught it the rules of the road by hand. Today’s software is teaching itself the rules of the road. When it makes a right turn on red, the most AI advanced teams will already be ready for it.
Now is the time for AI’s Phoenix project moment.
To build the future, sometimes we only need turn to the past.
############################################
I’m an author, engineer, pro-blogger, podcaster, public speaker, and the Chief Technical Evangelist at Pachyderm, a Y Combinator backed MLops startup in San Francisco. I also run the Practical AI Ethics Alliance and the AI Infrastructure Alliance, two open communities that advocate for safe and transparent AI.
############################################
This article includes affiliate links to Amazon.
############################################